
La regresión lineal, es una de las técnicas más conocidas y usadas dentro de la estadística en general y la Inteligencia Artificial en particular.
Se utiliza para para estudiar la relación entre variables, de modo que permita al investigador o analista de datos, estimar como influyen en el resultado o valor de un evento, un conjunto de variables a las que se llama predictoras, o independientes.
Su popularidad se basa, en que se adapta a una extensa variedad de situaciones, abarcando campos tan disimiles como la física, la investigación social, o la economía.
Utilidad de la regresión lineal
Podríamos emplear la regresión lineal para caracterizar la relación entre elementos o variables, de modo que nos permita calibrar parámetros en física; o predecir un vasto rango de fenómenos, como el efecto de decisiones económicas, el comportamiento de las personas, o la eficacia esperada de una inversión, o de la venta de un producto, en los análisis socioeconómicos, por citar ejemplos.
En esencia, la teoría de la regresión trata de explicar (predecir o pronosticar), el comportamiento de una variable (v. dependiente) en función de otra u otras (v. independiente), partiendo del supuesto de que ambas variables comparten una relación estadística lineal.
Siendo una técnica estadística, recomiendo entender su complejidad antes de utilizarla en proyectos de inteligencia artificial, donde lenguajes como Python, R o SPSS, nos adelantan mucho trabajo.
Saber de que va, nos ayudará a entender que hacemos y comprender los resultados que obtenemos; y sobre todo cuando su aplicación puede sernos de ayuda y cuando no.
Supuestos del modelo de regresión lineal
La regresión lineal como base
La regresión lineal no es posible analizarla con profundidad, si entre otras cosas, desconocemos los conceptos de correlación lineal y los diagramas de dispersión.
De modo resumido, digamos que la correlación lineal nos indica el nivel de relación que existe entre una variable y otra, la cual puede ser positiva o negativa.
Si es positiva significa que mientras crece una, también crece el valor de la otra y si es negativa sucede lo contrario.
Por otro lado, un diagrama de dispersión es una distribución espacial de los valores que toman están variables; por tanto nos puede ofrecer una idea bastante aproximada, sobre la relación entre ellas, incluso cuantificar de forma un tanto arcaica que grado de relación lineal existe, basta con observar la posibilidad de una recta que las una.
No obstante, en la vida real, los datos son muchos y raramente existe una relación que trace una línea perfecta, lo común y practico es todo lo contrario.
Estos ejemplos de diagramas de dispersión, son una muestra muy simple de tipos de datos, con diferentes tipos de relación, que nos ayudan a determinar la naturaleza de esta.
En definitiva el análisis de regresión lineal, ofrece una función que representa una recta en el espacio y esta recta variará su inclinación, en dependencia de como la magnitud de estas variables se comporte.
Cuando hacemos un análisis de regresión estamos pasando de expresar una dependencia estadística, a representar o buscar representar una dependencia funcional, o sea a buscar la recta que mejor se adapta a los puntos y como esto influye en su inclinación.
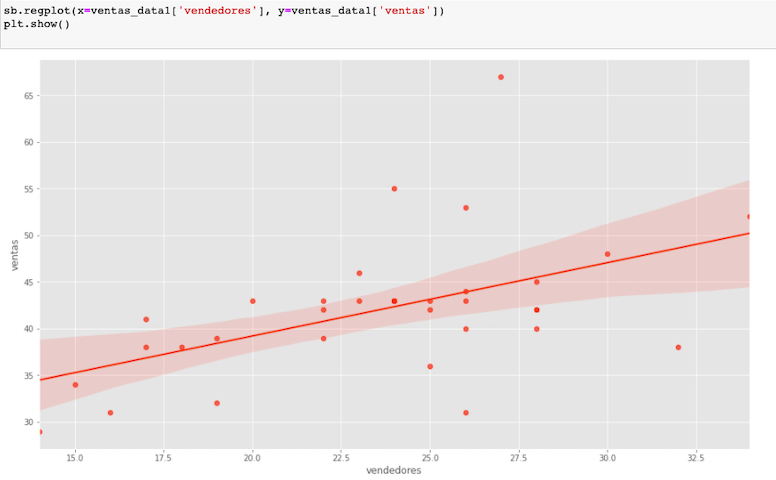
Supongamos que tenemos un conjunto de datos y necesitamos determinar en que medida se relacionan dos variables: la cantidad de quejas que emiten los clientes de un producto en internet, y la cantidad de productos devueltos en tienda.
El eje vertical muestra el número de quejas mensuales, y el horizontal el número de devoluciones mensuales expresado en porcentajes, con respecto a la venta.
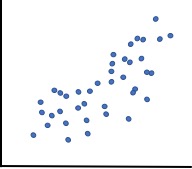
A simple vista, parece existir una relación positiva entre ambas variables: conforme aumenta el número de quejas mensuales en el foro de la compañía, también aumenta el número de devoluciones mensuales.
Podríamos añadir que solo medimos artículos de una determinada categoría; entonces para describir estos datos lo mas sencillo seria decir: que si aumentan las quejas en el foro, directamente aumentan las devoluciones pero esto; aunque correcto, es poco especifico.
¿Cómo obtener una descripción más concreta de los resultados?
Tenemos la opción de listar los datos concretos de que disponemos; pero esto, aunque preciso, no resulta demasiado informativo.
O podemos describir la tendencia que se observan en la nube de puntos que representan los datos, utilizando una función matemática simple, tal como una línea recta, ya que a simple vista una línea recta podría ser el punto de partida ideal para describir resumidamente la nube de datos y es línea es la que aporta la funcion de regresion lineal.
Funcion de regresión lineal
La fórmula de una línea recta es
Yi =B0 +B1Xi
Para poder determinar esta recta, lo primero seria determinar sus coeficientes ( B0 y B1) que son quienes definen la recta.
B1 es la pendiente de la recta: el cambio medio que se produce en el número de quejas (Yi) por cada unidad de cambio que se produce en el porcentaje de devoluciones (Xi) .
El coeficiente B0 es el punto en el que la recta corta el eje vertical: el número medio de quejas que corresponde a un mes con porcentaje de devolución cero.
Conociendo los valores de estos dos coeficientes, es fácil reproducir la recta y describir con ella la relación existente entre ambas variables.
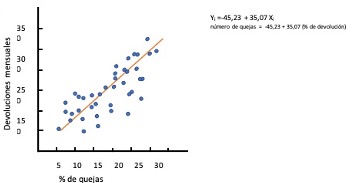
En este modelo, vemos que la recta hace un buen seguimiento de la distribución de los datos.
La formula obtenida nos da una recta (Bi) que indica que como promedio a cada incremento en el porcentaje de quejas, corresponde un incremento devoluciones (Yi).
Nota Importante: Si vemos el inicio de la recta B0, notamos que un mes sin quejas podría tener -45 quejas, lo cual no es sencillamente posible.
Aunque el origen de B0 nos brinda información sobre lo que podría ocurrir si estimamos hacia abajo la tendencia observada en los datos, hasta llegar a un mes sin quejas partiendo del hecho de que ese caso nunca ha ocurrido, podemos cometer un error de método al pronosticar resultados en un rango de valores desconocido, lo cual es un riesgo alto e innecesario en un análisis de regresión.
Existen otras técnicas para ello, no obstante, podríamos mejorar este estudio añadiendo todos los posibles escenarios, por ejemplo hurgar en los datos hasta hallar meses con esas características.
La mejor recta de regresión
Queda claro que la mejor recta es la que se adapte a la nube de puntos, pero en la realidad ningún conjunto de datos muestra una línea que se adapte a todos, y si así sucediera, lo aconsejable, es revisar el origen de esos datos de un modo exhaustivo.
En nuestro ejemplo, seria posible trazar muchas rectas diferentes, pero entre ellas se trata de hallar, la que puede convertirse en el mejor representante del conjunto total de datos.
Existen diferentes procedimientos para hallarla, de modo que ajustemos nuestra función.
Uno de los más conocidos y usados, es aquel que hace mínima la suma de los cuadrados de las distancias verticales entre cada punto y la recta. (método de los mínimos cuadrados)
Esto significa que, de todas las rectas posibles a dibujar en nuestro conjunto de datos, existe una y solo una, que consigue que las distancias verticales entre cada punto y la recta sean mínimas.
Esta se logra se elevando todas las distancias al cuadrado para anular su signo, ya que al ser opuestas (negativas y positivas), se anularían al sumarlas.
Bondad de ajuste
El concepto bondad de ajuste, parte de la idea de que incluso la mejor recta puede no ser una buena representación de los datos.
Por tanto, hay que añadir a la recta y su formula, alguna indicación de su grado que sea precisa, o sea necesitamos información útil, que nos permita conocer con que grado de fidelidad, la recta describe la pauta de relación, que pueda existir en los datos.
¿Cómo podemos cuantificar ese mejor o peor ajuste de la recta?
Hay muchas formas de resumir el grado en el que una recta se ajusta a una nube de puntos
Podríamos utilizar la media de los residuos, o la media de los residuos en valor absoluto, o las medianas de alguna de esas medidas, o alguna función ponderada de esas medidas, etc.
Una medida de ajuste, muy usada y aceptada es calcular el cuadrado del coeficiente de correlacion R2, conocido también como coeficiente de determinación R2.
R2 toma valores entre 0 y 1 (0 cuando las variables son independientes y 1 cuando entre ellas existe relación perfecta).
La utilidad de este indicador estriba en la simplicidad de su interpretación.
R2 representa el grado de ganancia o efectividad con que podemos predecir una variable, basándonos en el conocimiento que tenemos de una o más variables, dicho en lenguaje estadístico:
expresa la proporción de varianza de la variable dependiente, explicada por la variable independiente.
Si queremos, por ejemplo, pronosticar el número de devoluciones, sin conocer otra variable, podemos utilizar la media del numero de devoluciones, pero si tenemos información sobre algún otro elemento(variable) y conocemos su grado de relación con las devoluciones; el pronóstico mejorará
El valor R2 indica que si conocemos el porcentaje de devoluciones, mejoraremos en ese porciento, nuestra capacidad para conocer el numero de quejas.
Variabilidad de la regresión
Ya sea que analicemos solo dos variables, lo que en estadística se denomina regresión simple, o más de dos (regresión múltiple), el análisis de regresión lineal sigue en esencia las mismas pautas.
Como dije antes es una técnica muy útil para explorar y cuantificar la relación entre una variable llamada dependiente o criterio (Y) y una o más variables llamadas independientes o predictoras (X1, X2, …, Xn), así como para desarrollar una ecuación lineal predictiva.
Además, el análisis de regresión lleva asociados una serie de procedimientos de diagnóstico que informan sobre su idoneidad y que ofrecen ayuda para mejorarlo, no obstante es importante entender que el análisis de regresión no expresa causalidad, o sea no indica que una variable cause tal o mas cual efecto, sino que indica relación.
Esto es muy importante entenderlo y tenerlo presente.
Regresion simple
Conociendo que un análisis de regresion simple incluye una variable dependiente y una independiente o predictora, iremos directamente a conocer el significado de sus resultados

Residuos
Son las diferencias que existen entre las puntuaciones observadas y los pronósticos obtenidos en la recta.
R2 corregida:
Funciona como una corrección a la baja de R, es útil cuando los casos son pocos y las variables independientes muchas, ya que R2 puede dar valores altos artificiales o poco confiables, al considerar en su calculo p como el numero de variables independientes, mejora el ajuste.
Error típico de estimación
Normalmente es inversamente proporcional a la calidad del ajuste. En esencia es la desviación típica de los residuos y lo que mide es aquella parte de variabilidad de la variable dependiente, que no explica la recta de regresion.
Coeficientes de regresión parcial
Son los componentes de nuestro análisis, que conforman la ecuación de regresion, donde
B0 es el coeficiente que corresponde a la constante que expresa el origen de la recta
Y B1 seria la pendiente, que muestra el cambio medio que corresponde a la variable dependiente, por cada cambio en la variable independiente.
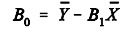
Coeficientes de regresión estandarizados
Se les conoce también como coeficientes beta, y son los coeficientes de la ecuación de regresion, que se obtiene una vez que se estandarizan la variables originales, lo cual se logra convirtiendo las puntuaciones directas en típicas. En la regresion simple su coeficiente coincide con el coeficiente de correlacion de Pearson
Puntuaciones típicas.
Explicaré muy rápido que es esto de convertir las puntuaciones de directas a típicas.
Digamos que las puntuaciones directas son las que obtenemos del estudio, o sean son aquellas que se encuentran en nuestra nube de datos, y a las que durante el análisis de regresión intentamos hallar su relación con respecto a una recta.
Sin embargo, existe un método alternativo que nos permite para expresar esas puntuaciones directas, pero con respecto al grupo de datos y es tipificando los datos .
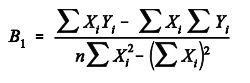
Como puede verse, obtenemos la diferencia de la puntuación (X), con la media del grupo de datos(M) , o sea nos da la distancia al punto central de la distribución que luego dividimos entre la desviación típica.
Las puntuaciones típicas se encargan de expresar que distancia hay entre las puntuaciones directas y la Media, es decir, indican cuantas Desviaciones Típicas hay desde la puntuación hasta la Media.
Su importancia radica, en que muestra la relación entre puntuaciones con independencia de la variable, o la unidad de medida, y esto permite comparar puntuaciones en escalas diferentes.
Una nota importante es que la Media y Varianza de las distribuciones tipificadas son siempre iguales a 0 y 1.
Regresión múltiple
La regresión lineal permite realizar el análisis con mas de una variable independiente y, por lo que es posible emplear la regresión múltiple.
La cuestión es que en ese caso la ecuación de regresión, deja de definir una recta en el plano, y pasa a mostrar un hiperplano, en un espacio que es ahora multidimensional.
Esto quiere decir que si con una variable dependiente y dos independientes, necesitamos tres ejes para representar su diagrama de dispersión, para tres variables independientes necesitaremos cuatro y así sucesivamente, lo cual es poco practico e inútil
La solución es partir de la ecuación del modelo
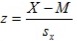
Ahora la variable dependiente (Y), expresa la combinación lineal de un conjunto de K variables independientes (Xk), donde cada una de las cuales, posee un coeficiente (βk) que indica el peso relativo de esa variable en la ecuación.
La ecuación incluye además, una constante (β0) y un componente aleatorio que son los residuos (los residuos: ε) encargados como ya vimos antes de recoger todo lo que las variables independientes no son capaces de explicar.
Este modelo, se basa en varios supuestos estadísticos que no explicaré aquí: linealidad, independencia, normalidad, homocedasticidad y no-colinealidad y de los que hable en un articulo anterior.
Y al igual que en la regresion simple, existe una ecuación mínimo-cuadrática, que se encarga de estimar los valores de los coeficientes beta del modelo de regresión, intentando hacer que las diferencias al cuadrado entre los valores observados (Y) y los pronosticados ( ) sean mínimas, la cual tiene esta estructura.
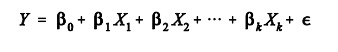
Coeficientes parciales
Indican como incide cada variable independiente sobre la variable dependiente, manteniéndose constantes el resto de las variables independientes, o sea:
un coeficiente de correlación parcial expresa el grado de relación existente entre dos variables tras eliminar de ambas el efecto debido a terceras variables
Estos coeficientes deben ser analizados con cuidado, porque no son independientes entre sí.
El valor concreto estimado para cada coeficiente se ajusta teniendo en cuenta la presencia del resto de variables independientes, de ahí el nombre de parcial.
Tambien es importante la existencia de colinealidad (alto grado de asociación entre algunas o todas las variables independientes) en estas variables, lo que se asocia con que el signo del coeficiente de regresión parcial de una variable, pueda no ser el mismo que el del coeficiente de correlación simple entre esa variable y la dependiente.
Esta diferencia de signo, se atribuye a los ajustes que se llevan a cabo para mejorar la ecuación.
Coeficientes de regresión estandarizados en la regresión múltiple.
Ya sabemos que los coeficientes Beta están basados en las puntuaciones típicas y, por tanto, son directamente comparables entre sí, los que les permite mostrar la cantidad de cambio, en puntuaciones típicas, que se generará en la variable dependiente por cada cambio de una unidad en la correspondiente variable independiente, manteniendo constantes al resto de variables independientes.
Su valía es especialmente importante, al ser muy útiles en mostrar la importancia relativa de cada variable independiente en la ecuación de regresión.
En general, una variable tiene tanto más peso (importancia) en la ecuación de regresión, cuanto mayor (en valor absoluto) es su coeficiente de regresión estandarizado.
Y hasta aquí, ahora al obtener los resultados de un análisis de regresión o plantearte emprende uno cuando te enfrentes a un grupo de datos y un problema a resolver, espero que tengas algo mas claro que estas viendo, y porque.
Espero modestamente que este artículo, sirva de ayuda a alguien.
Gracias
El amor siempre empieza soñando y termina en insomnio
R.Arjona