Una necesidad que puede surgir al programar, es tener que comparar fechas en Python. Implementar las comparaciones no es algo complejo y para ello emplearemos operadores de comparación de uso común como <, >, <=, >=, != y otros, dentro del modulodatetime().
import datetime
# fecha in yyyy/mm/dd format
fecha_1 = datetime.datetime(2020, 4, 6)
fecha_2 = datetime.datetime(2019, 12, 30)
fecha_3 = datetime.datetime(2019, 1, 1)
# la comparacion devolvera verdadero o falso
print("La fecha_1 es mas nueva que la fecha_3 : ", fecha_1 > fecha_3)
print("La fecha_2 es mas vieja que la fecha_3 : ", fecha_2 < fecha_3)
print("La fecha_3 es igual a la fecha_1 : ", fecha_3 == fecha_1)
print("La fecha_1 no es la misma que la fecha_2 : ", fecha_1 != fecha_2)
La salida que obtenemos es :
La fecha_1 es mas nueva que la fecha_3 : True
La fecha_2 es mas vieja que la fecha_3 : False
La fecha_3 es igual a la fecha_1 : False
La fecha_1 no es la misma que la fecha_2 : True
En este otro ejemplo comparamos varias fechas que entramos por teclado.
# Entramos por teclado las fechas
dia_1, mes_1, año_1 = [int(x) for x in input("Introduzca fecha del primer envio"
"(YYYY/MM/DD) : ").split('/')]
primera = date(dia_1, mes_1, año_1)
dia_2, mes_2, año_2 = [int(x) for x in input("Introduzca fecha del segundo envio"
"(YYYY/MM/DD) : ").split('/')]
segunda = date(dia_2, mes_2, año_2)
dia_3, mes_3, año_3 = [int(x) for x in input("Introduzca fecha del tercer envio"
"(YYYY/MM/DD) : ").split('/')]
tercera = date(dia_3, mes_3, año_3)
# Check the dates
if primera == segunda:
print("Es raro que ambas se hicieran en mismo dia")
elif tercera > primera:
print("es correcto")
else:
print("Debe analizarse")
Y esto es todo, espero sinceramente que este post, sirva a alguien.
No discutas nunca con un imbécil, te llevará a su terreno y allí te ganará por experiencia
Fusionar dos diccionarios en Python 3.5, es algo que puede resultar común en nuestra aplicación.
El procedimiento varia según la versión de Python que usemos, en nuestro caso es la 3.5 , siguiendo las indicaciones de las convencionesPEP 448
Lo que obtenemos es un nuevo diccionario t , con todos los valores, donde están sobreescritos los valores del segundo diccionario (b), por los del primero (a)
Espero modestamente que este artículo, sirva de ayuda a alguien.
Gracias
“….El amor siempre empieza soñando y termina en insomnio“
En otros artículos he hablado de decoradores, en este, me referiré al uso de staticmethod en Python y sus características.
Todos sabemos que Python está orientado a objetos y que las clases son la base de su programación, por eso el uso de decoradores es una ayuda importante en el manejo de estas.
staticmethod es un decorador que nos permite usar una funcion dentro de una clase sin que esta reciba argumentos.
Su forma de escribirlo, es colocando una arroba delante
@staticmethod
Este decorador permite llamar a una clase, aunque esta aun no haya sido convertida en un objeto.
Veamos un ejemplo, que ya he empleado al hablar de decoradores antes:
class boxeador(object):
def __init__(self):
pass
@staticmethod
def esquina():
print("Has tenido suerte, tu esquina aun no tiene color")
def main():
b = boxeador()
b = b.esquina()
if __name__ == '__main__':
main()
Como ven hemos podido llamar a esquina() sin que esta tenga ningún parámetro.
Si eliminamos el decorador recibiríamos este error:
TypeError Traceback (most recent call last)
<ipython-input-22-0a10128b3e82> in <module>
12
13 if __name__ == '__main__':
---> 14 main()
<ipython-input-22-0a10128b3e82> in main()
8 def main():
9 b = boxeador()
---> 10 b = b.esquina()
11
12
TypeError: esquina() takes 0 positional arguments but 1 was given
'
Esto nos está indicando un error de tipo, que nos dice que a pesar de que la función esquina no tiene argumentos (parámetros), la hemos llamado como si lo tuviera.
Y hasta aquí, como siempre espero que sirva de ayuda a alguien.
Un saludo
Entrena duro y en silencio, que el éxito sea tu grito
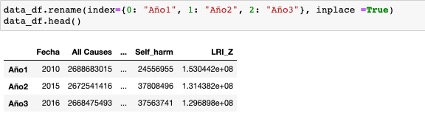
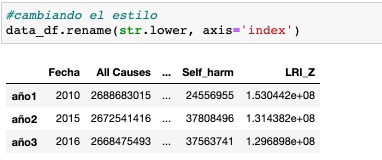
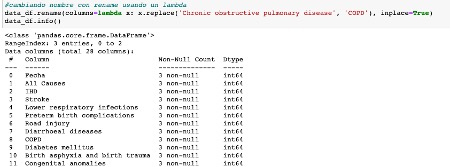
Las vías que conozco, para cambiar el nombre a una columna son tres . Podemos hacerlo con el método rename(), el cual puede aplicarse directamente a la columna, o pasarlo a través de una funcion lambda.
Ojo, es posible que haya más posibilidades, me refiero a las que uso y conozco.
Cambiar el nombre a una columna con Pandas
El método rename(), se utiliza justo para modificar la etiqueta de los ejes, al aplicarlo nos devolverá un nuevo dataframe con los valores aplicados. Su sintaxis es:
maper: Ya sea un diccionario o una función , indica las transformación a aplicar al eje dado. Este parámetro y el eje se emplean para indicar que valores y ejes recibirán el cambio.
index: Nos permite establecer el eje. Si empleamos maper, index =0 , es lo mismo que maper = index
columns: Indica las columnas, si su valor es cero o se ignora, significa que es el mismo que maper.
axis: tiene por defecto el valor 0, que indica el índice, el valor 1 indica columnas. Pueden emplearse colocando el nombre del eje(índice, columnas), o el numero (0,1). El valor que recibe por defecto es el del índice.
copy: Su valor determinado es True, y esto garantiza copiar también los datos subyacentes.
inplace: valor por defecto False, si se convierte a True, al devolver el nuevo dataframe la copia anterior se ignora.
level: valor por defecto None, indica el numero o nombre del nivel. Si existen índices multiples solo modificara en el nivel indicado.
error: acepta raise o ignore, y ese último es su valor por defecto. Ignora el error del tipo keyerror, cuando index o columns contienen etiquetas que no existen.
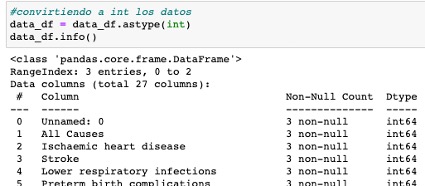
Tenemos el siguiente dataframe:
Aplicándolo directamente seria algo asi:
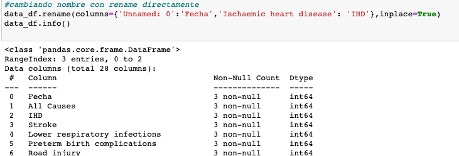
Renombramos varias columnas usando mapping en las columnas Unnamed: 0 e Ischaemic heart disease, para ello pasamos los valores nuevos, en forma de diccionario.
En Python se dan dos tipos de errores principales. Los errores de sintaxis y las excepciones.
Los errores de sintaxis o interpretación, son muy comunes.
Su estructura suele ser la que aparece en el ejemplo siguiente:
>>> while True print('Hello world')
File "<stdin>", line 1
while True print('Hello world')
^
SyntaxError: invalid syntax
En este caso el intérprete de Python, reproduce la línea responsable del error y muestra una “flecha” que apunta al primer lugar donde se detectó este.
En el ejemplo, el error se detecta en la función print(), ya que faltan dos puntos (‘:’) antes del mismo.
El error ha sido provocado (o al menos detectado) en el elemento que precede a la flecha. Dentro de la declaración del error se muestran el nombre del archivo y el número de línea, lo cual te permitirá localizar con facilidad su ubicación exacta.
Excepciones
Se llama excepciones a errores detectados durante la ejecución del código que no son incondicionalmente fatales.
Esto quiere decir que pueden ser resueltos con una condición y por ello Python nos ofrece condiciones para manejarlos.
Cuando no son gestionadas por el código, resultan en en mensajes de error:
Veamos algunos ejemplos.
>>> 10 * (1/0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
>>> 4 + spam*3
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'spam' is not defined
>>> '2' + 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
Explicando un poco el ejemplo vemos que estrutura tiene.
En Python existen diferentes tipos de excepciones y el tipo a que corresponde se imprime como parte del mensaje.
La cadena mostrada como tipo de la excepción es el nombre de la excepción predefinida que ha ocurrido.
Esta convención es válida para todas las excepciones predefinidas del intérprete, y aunque no tiene por que ser así para excepciones definidas por el usuario, se recomienda su uso.
La parte anterior del mensaje de error muestra el contexto donde ocurrió la excepción, en forma de seguimiento de pila.
En general, contiene un seguimiento de pila que enumera las líneas de origen; sin embargo, no mostrará las líneas leídas desde la entrada estándar.
El resto del mensaje provee información basado en el tipo de la excepción y qué la causó.
La última línea de los mensajes de error indica qué ha sucedido.
Por último debemos saber que los nombres de las excepciones estándar son identificadores incorporados al intérprete (no son palabras clave reservadas).
Puedes rotar los tick labels en Matplotlib, empleando el método tick_params() sobre los ejes (Axes objects), con que trabaja la librería, indicándole exactamente que quieres hacer.
ax.tick_params(axis='x', rotation=60)
#Esto rotará 60 grados las etiquetas, sobre el eje de las x.
Conoce mas como trabajar con los ticks en este árticulo
Espero modestamente que este artículo, sirva de ayuda a alguien.
Gracias
…..lo que realmente importa no es lo que te da la vida, sino lo que haces con ello….
En este post realizaré un análisis de regresión, en el que tomaremos una set de datos preparado previamente.
El problema real al que nos enfrentamos, es determinar la relación que pueda existir entre la cantidad de ventas de la empresa “El Dorado”, y el numero de vendedores que la han integrado durante el periodo que se estudia, que son 36 meses o sea los últimos 3 años.
El departamento ha cambiado de responsable en varias ocasiones, y cada uno ha aplicado políticas diferentes de ventas, algunas intensivas, buscando mayor productividad en las ventas, a bases de estímulos como bonos, primas, ascensos, etc; y en otras ocasiones, en cambio, se han aplicado medidas extensivas incrementando el numero de vendedores, en una afán por ampliar la cobertura de ventas.
Lo que vamos a hacer es implementar un análisis de regresión lineal.
La regresion lineal es una técnica estadística, que el machine learning adoptó y que incluye como uno de los algoritmos supervisados.
He escrito hace unos meses algún articulo sobre regresion lineal y resumiendo lo que hara este análisis es obtener una recta que se acerque lo mas posible a todos los puntos de datos representados en un plano.
En nuestro caso es una regresion simple (participan dos variables ) y la recta que buscamos obtener es, la mejor posible.
Esto quiere decir que de todas las rectas esta sea la que mejor se adapte al conjunto de puntos, lo que le permitirá tendencialmente estimar o predecir valores, dentro del contexto de datos estudiados.
La recta tiene forma esta forma Y = mX + b; donde Y es el resultado obtenido, X es la variable, m la pendiente (o coeficiente) de la recta y b el valor constante, que gráficamente expresa el “punto donde cuando X tiene valor cero, se produce la intercepción o corte con el eje Y.
Su optimización o ajuste se logra aplicándole una función llamada de mínimos cuadráticos, o también conocida de error cuadrático.
Su nombre obedece a que esa funcion intenta minimizar el error existente entre los puntos o dados y los obtenidos, elevendo al cuadrado sus valores para evitar que se anulen.
De este modo el algoritmo, se centra en minimizar el coste de dicha función
Recordemos que los algoritmos de Machine Learning Supervisados, aprenden por sí mismos.
Utilizaremos un archivo de datos que ya tenemos, y que muestra el número de ventas y vendedores por meses; o sea tendremos dos columnas: vendedores y ventas.
Y nuestro en nuestro análisis de regresión, lo que vamos a intentar es determinar a partir de los vendedores que tenemos, que valor podemos esperar en la ventas de acuerdo, a la relación dada entre ambas variables.
Trabajaremos con Jupiter Notebook,utilizaremos las librerías Pandas, SkLearn, Seaborn, Numpy, de modo que comenzaremos por ahí.
Importamos las librerías
Cargamos nuestro archivo en un dataset de pandas después de leerlo, definiendo el separador de columnas.
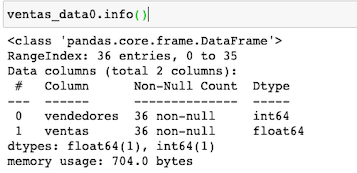
Adquirimos la información de nuestro dataset, con el método info(). Observamos que tenemos dos tipos de datos : enteros en columna vendedores y decimales en la columna ventas.
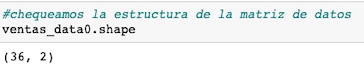
Comprobamos la estructura del dataset, con el método shape, que nos dice que tenemos efectivamente dos columnas y 36 registros en cada una.
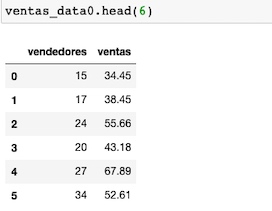
Con head(), visualizamos las 6 primeras filas de nuestro dataset
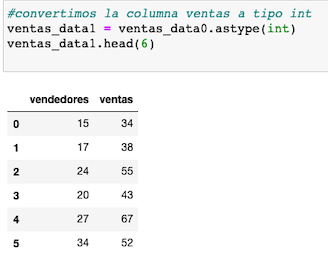
Convertimos por comodidad la columna venta a tipo entero, empleando el método astype() y guardamos esa transformación en un nuevo dataset, que es con el que continuaremos trabajando.
Definimos con columns(), los encabezados de las columnas
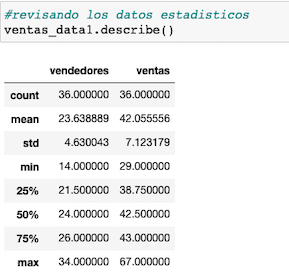
Obtenemos los valores estadísticos de nuestro dataset con el método describe()
Observamos entre otros valores, que la media de vendedores es 23, con una desviación de 4,63; mientras que la de ventas es 42 millones y su desviación es de 7.12.
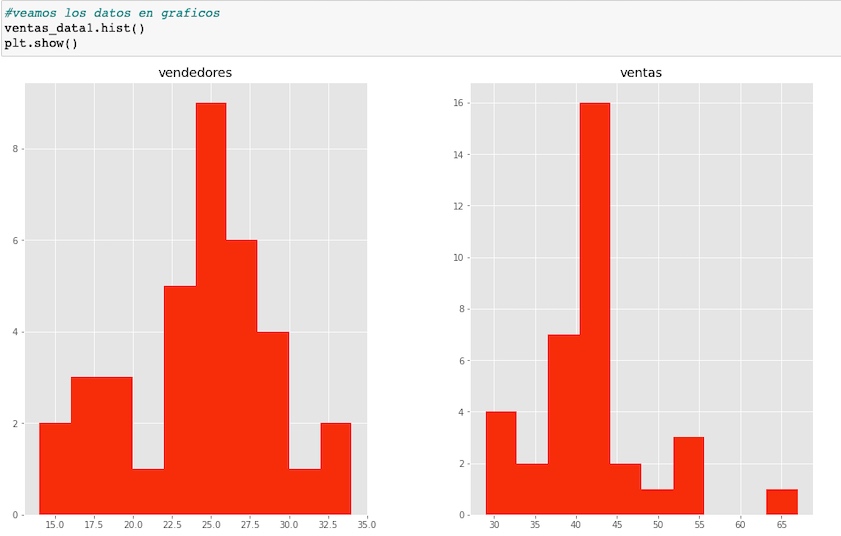
Visualizamos los datos, en gráficos, mostrando las columnas por separados
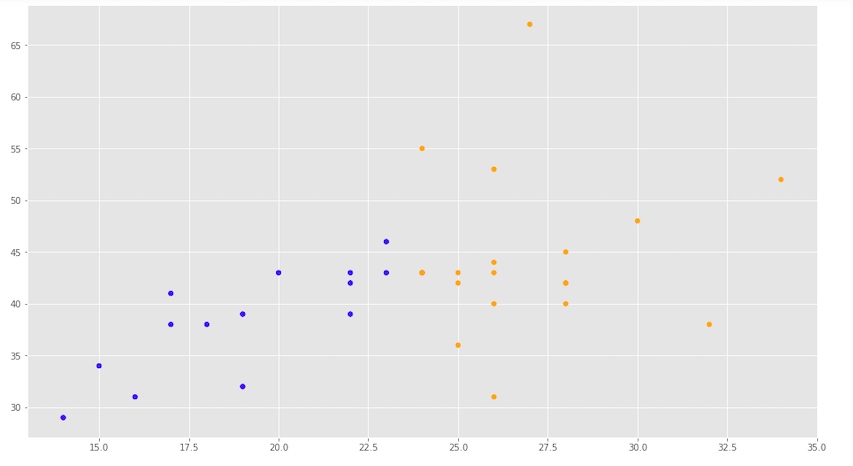
Empleando scatter mostramos los puntos coloreados, separando los colores a partir de la media de vendedores (23)
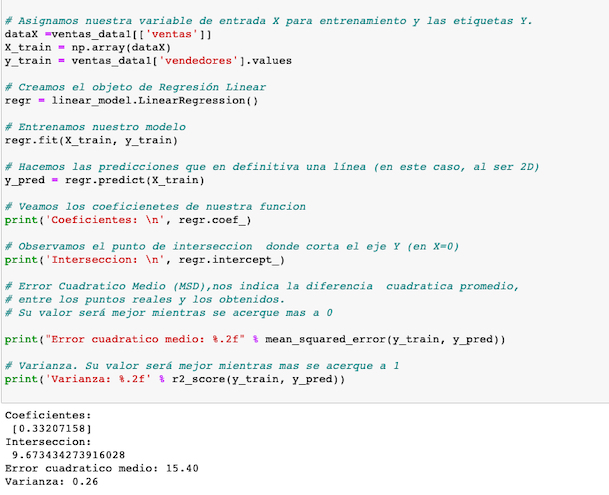
En este punto creamos nuestra recta de regresion y visualizamos los coeficientes que la componen nuestra recta.
Nuestro error cuadrático no es elevado pero es alto y nuestra varianza esta más cerca de 0 que de 1, por lo que este modelo tal vez podría mejorarse.
La intersección (b), tiene un valor de 9,67…. donde se corta la recta cuando el valor en X es 0
En función de observar el comportamiento del modelo, asignamos valores diferentes para ver su comportamiento
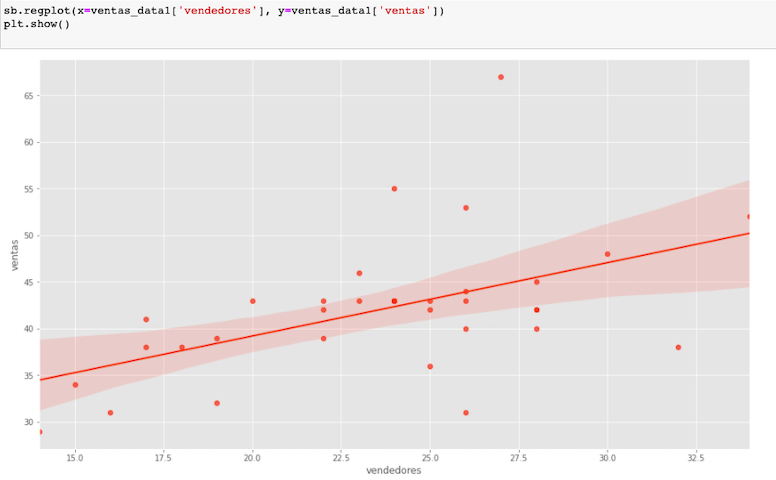
Ahora visualicemos la recta dentro de nuestro gráfico
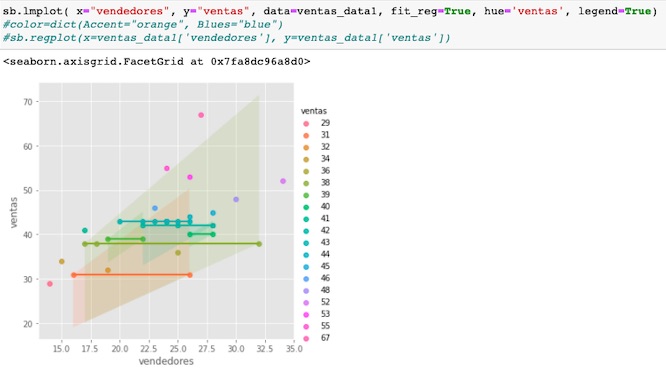
Podemos observar nuestros datos de diferentes formas, en este caso con la librería seaborn, vemos el comportamiento de los datos en los diferentes periodos y su relación.
Para mejorarla tenemos varios caminos, podemos aplicar métodos como el gradiente, podemos hurgar en los datos y añadir más variables predictivas, referidas por ejemplo a la competencia, la innovación o la aceptación de los productos, pasando de una regresión simple a una regresión múltiple, podríamos también ampliar la cantidad de registros buscando mas años, desechar los valores extremos, etc.
En otros artículos iré aplicando algunos de estos métodos, haciendo referencia a estos mismos datos.
Espero modestamente que este artículo, sirva de ayuda a alguien.
Gracias
«El amor es la guerra perdida, entre el sexo y la risa»
Hablemos del mensaje de error _io.TextIOWrapper, que suele aparecer cuando intentamos imprimir un determinado archivo en Python.
Realmente aunque lo consideramos un error no lo es, sino que es mas bien un mensaje que nos indica que estamos intentando imprimir algo que no es correcto.
Veamos un ejemplo de como debería estar planteado nuestro código:
def imprimir():
#Abrimos el archive para imprimir.txt.
nuevo_file = open('imprimir.txt', 'r')
#lo leemos
contenido = nuevo_file.read()
#Imprimimos los datos dentro del objeto contenido
print(contenido)
Revisa bien los elementos del código y recuerda que en Python todo, son objetos a los cuales les vamos aplicando funciones, cuyo tipo no necesita ser definido de antemano y que pueden variar su contenido.
Espero modestamente, que este post, sirva de ayuda a alguien.
La turba enardecida se convierte en manada, y la manada mata.
Veamos como calcular el porcentaje de una columna en Pandas, para lo cual usaremos sus propia función sum()
Como sabemos Pandas trabaja con dataframes o marcos de datos y también queda claro, que el porcentaje se obtiene dividiendo el valor total entre la suma de todos los valores y luego multiplicando ese resultado por 100.
Lo que hacemos, no es otra cosa que aplicar este mismo procedimiento a la columna que deseamos analizar.
Primero sumaremos toda la columna con sum(), que es el método que se emplea para sumar en Pandas.
import pandas as pd
import numpy as np
#tenemos una matriz accesorios con dos columnas (periodos y cantidad)
accesorios = {
'periodos': ['periodo_1', 'periodo_2', 'periodo_3',
'periodo_4', 'periodo_5', 'periodo_6',
'periodo_7'],
'cantidad': [100, 40, 47, 78, 89, 78, 64]}
# instanciamos accesorios como un dataframe de pandas,
# y definimos sus columnas
accesorios = pd.DataFrame(accesorios,
columns = ['periodos',
'cantidad'])
# calculamos la columna porcentaje, la cual se añade automaticmente # al dataframe accesorios. Dividimos la cantidad entre la suma de
# la columna y la multiplicamos por 100
accesorios['porcentaje'] = (accesorios['cantidad'] /
accesorios['cantidad'].sum()) * 100
accesorios
Como ven hemos calculado el porcentaje de la columna para saber que magnitud del total representa cada período.
En esta ocasión hablaré de como redondear decimales en Pandas con round() y decimal().
Ya en antes, he hablado, de lo que significa, y cómo aplicar el redondeo de la mejor forma posible en Python.
Sabemos, que existen múltiples ocasiones, en las que podemos necesitar sustituir un valor de tipo entero, por otro con una cantidad de decimales dada; o directamente asignar solo una cantidad de decimales a todos los valores dentro de una dataframe.
Veamos un ejemplo para mostrar las diferentes opciones.
Primero importamos las librerías.
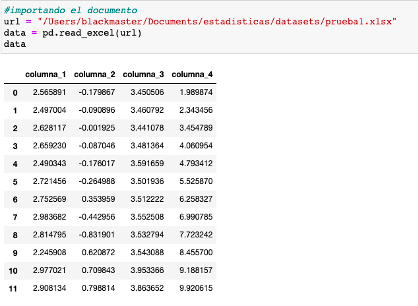
Importamos el dataframe
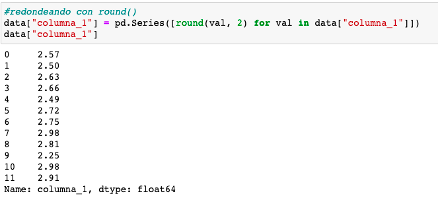
Redondear decimales usando round() en Pandas
Es una función que redondea un número de coma flotante, al número de lugares decimales proporcionados como segundo argumento de la función.
Su sintaxis es round(value, numero de decimales)
En este ejemplo redondeamos la columna 2 de un dataframe
Primero aplicamos la función series() de Pandas, definimos la función round() con los espacios que deseamo, para luego aplicar un bucle for, para recorrer la columna.
En este caso la labor de round(), es colocar una coma flotante, y dejar la cantidad de decimales que le indicamos al redondear, como segundo parámetro.
Format() como apoyo
Otra forma, es utilizar format(), pero como su nombre indica, por si sola, no redondea, sino que formatea la salida de la cadena, dandole la estructura que deseamos.
format() es una propiedad de string, o sea trabaja con una cadenas, y por lo tanto no debe confundirse con valores numéricos
La sintaxis es algo como lo que sigue, cuando la usamos en solitario, aunque existen multiples combinaciones para aplicar formato.
En este caso estamos formateando la salida de un valor a porcentaje con solo dos decimales.
df['columna3'] = pd.str(["{0:.2f}%".format(val * 100) for val in df[' columna3']])
El formato de cadena le permite representar los números como desee. Puede cambiar el número de lugares decimales que se muestran cambiando el número antes de la f.
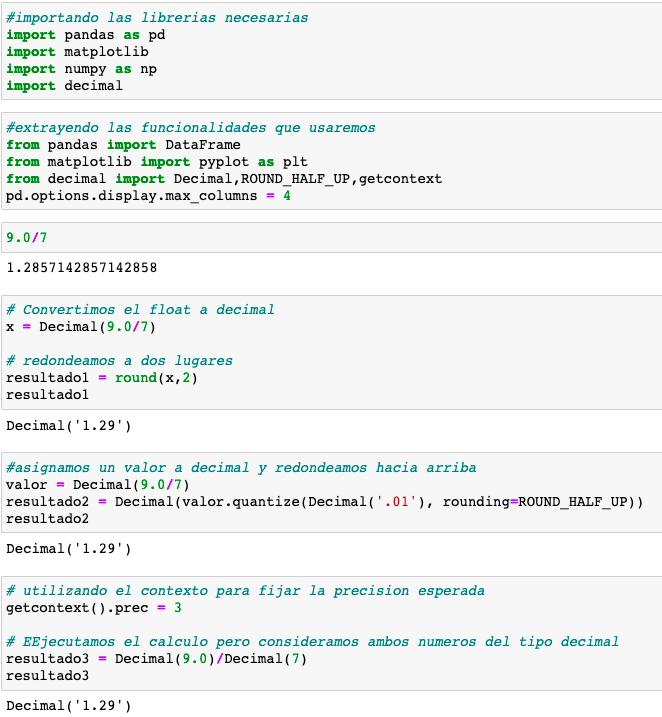
Redondear decimales usando Decimal
Cuando necesitamos una adecuada precisión es recomendable usar decimal, ya que es mucho mas adecuado que round(), si buscamos exactitud.