
Ante todo, esta es una solución para personas que trabajen en Mac con Python y la librería Pandas, para no programadores, la solución es otra.
Un problema común, es que al crear un archivo csv, cometamos una equivocación y nuestro archivo no se visualice correctamente, lo que nos traerá problemas, sí como es mi caso quiero emplearlo como dataset en Python.
Digamos que tengo un archivo del tipo Excel, con dos columnas «vendedores» y «ventas».
La columna «vendedores» tiene valores enteros, y la columna «ventas», valores decimales.
La dificultad a la que nos enfrentamos es que en Mac, para cambiar el separador hay que ir hasta el propio registro que establece los separadores decimales, de todo el sistema, ya sea directamente o mediante comandos(solución para no programadores).
Siendo como soy, enemigo de tocar lo que no debo tocar, para evitar errores futuros de los cuales olvidaré la causa, busqué una solución más sencilla, que ya existe en el «abc» de Pandas. El argumento sep().
Cuando creaba un csv, ya sea en formato UTF 8, o csv para Mac, lo que hacia era separarme las filas por , coma y no punto y coma.
Pandas resuelve esto fácilmente, con él parámetro sep(), que permite escoger el separador en una cadena dada.
Veremos la salida del mismo archivo dos veces, sin utilizar sep y dándole uso.
Sin usar sep
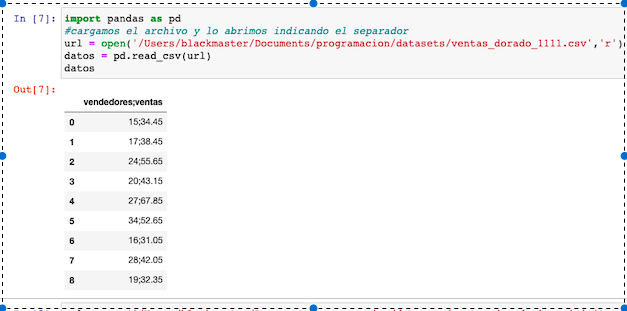
Utilizando sep
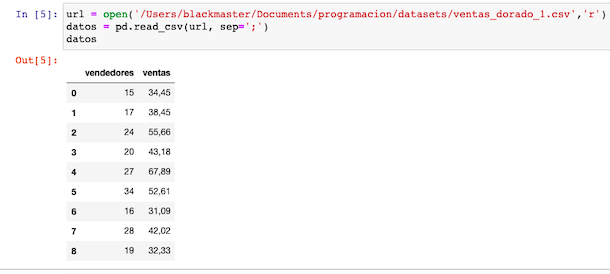
Espero modestamente que este artículo, sirva de ayuda a alguien.
Gracias
Y yo tenia respuesta a todas sus preguntas, incluso a las que aún no se ha hecho.
Y