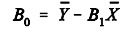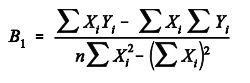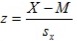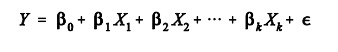Veamos como recuperar una imagen en Django, para que Django no la dibuje dinámicamente en función del usuario.
Cuando trabajamos en Django, es común colocar el avatar de nuestro usuario en el panel, si tenemos habilitado nuestro modulo "context_procesor", dentro de templates en nuestro archivo setting.py., podemos seguir las instrucciones siguiente.
La magia está, en que el método request(), nos traerá la instancia del user a toda pagina que tengamos, por tanto dispondremos de sus atributos, para el usuario visitante.
Recuperando una imagen en el html
Suponiendo que hemos creado nuestro modelo, nuestro form y nuestras url, podemos recuperar a nuestra imagen con
Crear prefijos a tablas y usarlos en consultas, es algo perfectamente posible de hacer en Laravel
Podemos crear un prefijo a todas las tablas de nuestra Base de Datos, basta con ir al archivo config/database.php, y en la opción prefix, y añadir el que queremos usar
Esta vez tocaré el tema de Matplotlib. Graficos de dispersion en linea, ya que matplotlib es una librería completamente pensada, para crear visualizaciones estáticas, animadas e interactivas en Python.
Esta capacidad la hace especialmente importante, para la visualización de datos en estudios de inteligencia artificial.
Su amplia capacidad le permite trazar diferentes tipos de gráficos en Python (gráficos : de dispersión, circulares, de líneas, histogramas, gráficos 3-D y muchos más.
Veremos en este articulo el uso de algunos de ellos: los de dispersión y los de línea.
En lo adelante, escribiré otros artículos sobre los otros tipos.
Gráficos de dispersión
Los gráficos de dispersión se utilizan para observar la relación entre variables y utiliza puntos para representar la relación entre ellas y cómo el cambio en una, afecta a la otra.
Gráficos de dispersión empleando el método plot()
El método plot(), acepta cuatro parámetros básicos, el eje de la x, el eje de la y, el tipo de marcador y el color de los puntos en el gráfico; e incluso estos dos últimos pueden obviarse.
De hacerlo plot(), colocará una línea por defecto, si no establecemos otro marcador, y el color azul.
La sintaxis es:
plt.plot(x, y, 'o', color='blue')
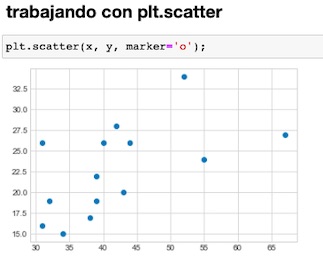
Gráficos de dipersión o scatter con el método pyplot()
El método se utiliza con la sintaxis siguiente:
matplotlib.pyplot.scatter()
El método scatter() en la biblioteca matplotlib se usa para dibujar un diagrama de dispersión.
El método scatter() toma los siguientes parámetros:
x_axis_data: una matriz que contiene datos del eje x
y_axis_data: una matriz que contiene datos del eje y
s: tamaño del marcador (puede ser escalar o una matriz de tamaño igual al tamaño de x o y)
c: color de secuencia de colores para rotuladores
marcador(marker): estilo del marcador
cmap- nombre de cmap
linewidths- ancho del borde del marcador
edgecolor- color del borde del marcador
alfa(opacidad): valor de mezcla, entre 0 (transparente) y 1 (opaco)
Excepto x_axis_data e y_axis_data, todos los demás parámetros son opcionales y su valor predeterminado es none.
Metodo plot() versus pyplot()
Los métodos plot() y pyplot() difieren sobre todo, en su capacidad para adaptarse a las características de que necesitamos dotar a los gráficos, para expresar mejor nuestros datos.
La diferencia entre ellos, estriba en el volumen del dataset, sobre todo.
pyplot() ofrece una configuración más avanzada, que le permite dibujar con colores y tamaños diferentes cada punto, lo cual le obliga a renderizar una y otra vez, mientras plot(), solo dibuja de un solo color y tamaño todo el set.
En unos cientos de datos puede no notarse la diferencia, pero en grandes datasets, el uso de memoria puede hacerse sentir.
Este artículo mostraré algunos ejemplos de visualizar nuestros datos utilizando la librería matplotlib y ambos métodos.
Utilizaremos los datos que tenemos ya preparados en un archivo csv, en principio con solo dos columnas, ventas en millones de euros y vendedores.
Comenzaremos importando las librerías y nuestro archivo
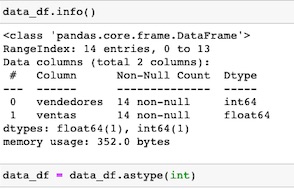
Examinamos la estructura del archivo y lo convertimos a int()
Para todas las gráficas de Matplotlib, se comienza creando una figura y un eje.
En su forma más simple, se pueden crear una figura y ejes de la siguiente manera:
figure(), es una instancia de la clase plt.figure(); la cual constituye un contenedor único que contiene todos los objetos que representan ejes, gráficos, texto y etiquetas.
Los ejes (axes), son a su vez una instancia de la clase plt.axes(), que se ve como el cuadro delimitador con marcas y etiquetas, que contendrá los elementos de la trama que componen nuestra visualización.
Normalmente utilizaré fig(); como la variable que contiene la instancia de figure, y ax() como la que contiene la instancia de la clase axes.
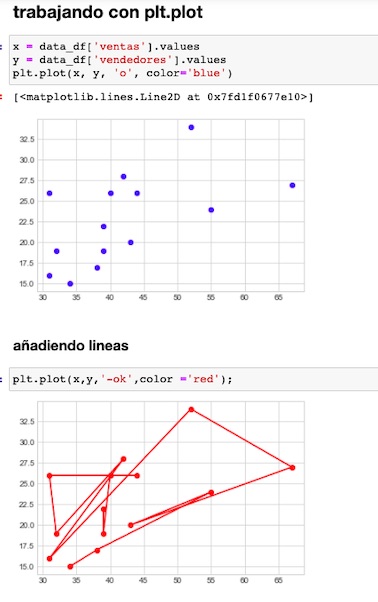
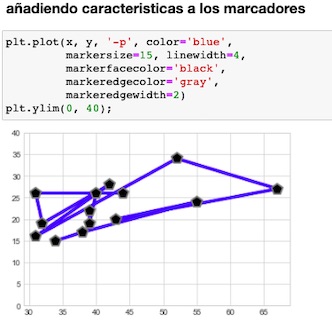
Visualizamos con el uso de plt.plot().
El tercer argumento que le pasamos a la función, indica el tipo de símbolo que emplearemos.
En la primera figura mostramos nuestros datos y en la segunda los unimos con una línea, utilizando '–‘
Los marcadores que usamos, pueden ser diseñados a medida, como se ve debajo
Podemos hacer lo mismo con plot.scatter()
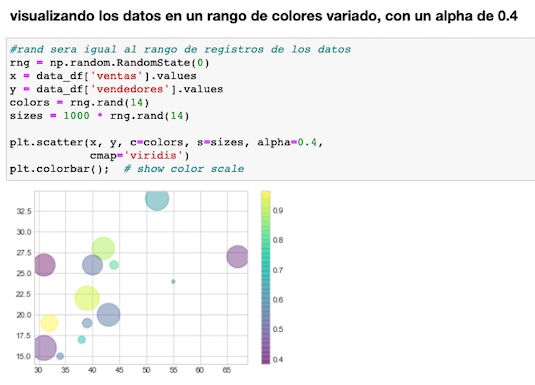
Emplearemos una función para trabajar nuestros gráficos. Veamos por ejemplo como mostrarlos en una gama de colores, que indican el peso de cada variable.
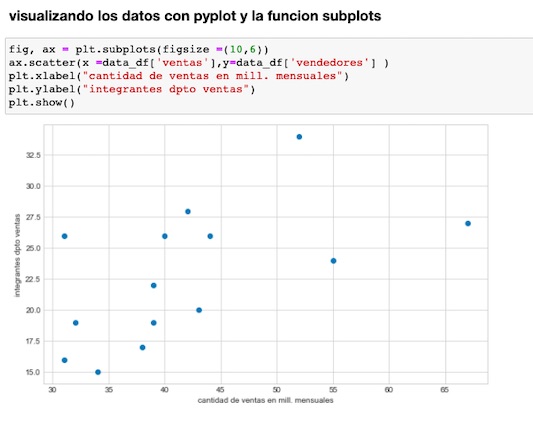
Podemos usar la función subplot() de pyplot(), para mostrarlos de diferentes formas. Importaremos primero un dataset, con cuatro columnas para trabajar con más datos.
La instancia de pyplot(), permite establecer el tamaño de la figura.
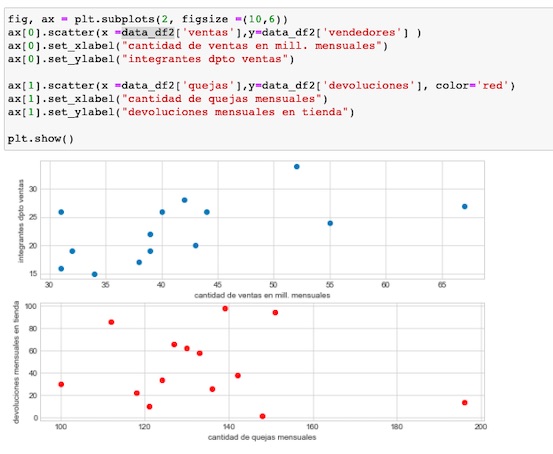
Usando el objeto ax devuelto, que se obtiene desde la función subplots(), y llamamos a la función scatter().
Mostremos varios gráficos en una sola visualización
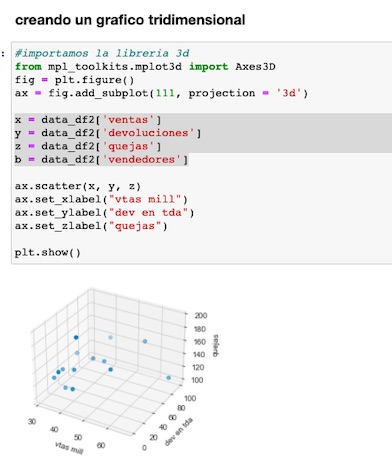
Podemos también crear un grafico tridimensional
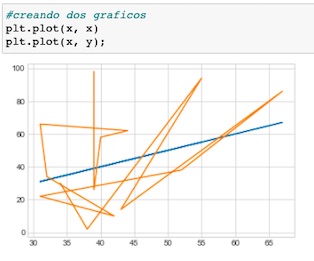
Gráficos de línea
El más sencillo de todos los gráficos es la visualización de una sola función del tipo y = f(x).
Veamos como crearlos
Creemos ahora varias líneas en un solo espacio
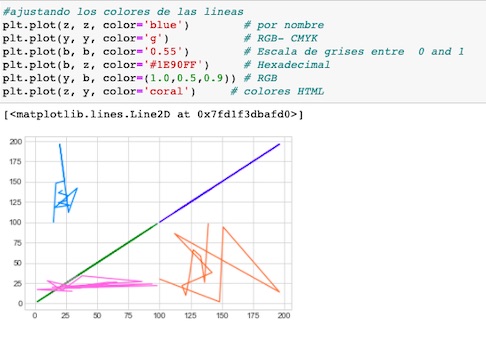
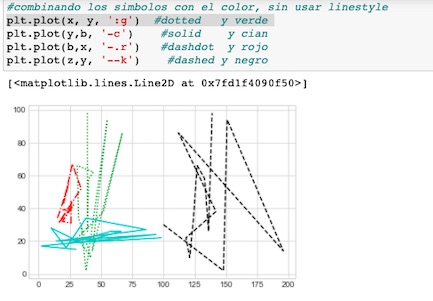
Podemos colorear las líneas con cualquier color, y pasándolo en diferentes formatos a través del parámetro color()
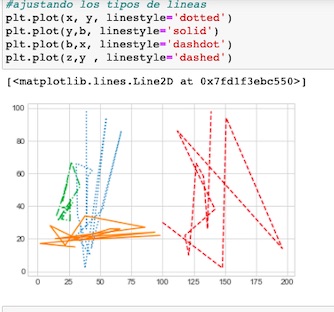
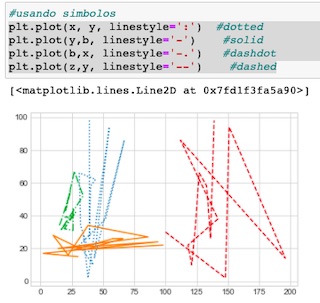
Podemos combinar emplear símbolos y denominaciones para escoger el tipo de línea con el parámetro linestyle()
Ahora combinemos pasándolo directamente como un parámetro más, color y estilo de línea sin emplear linestyle()
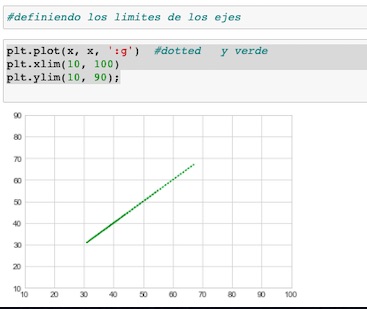
Matplotlib, nos permite ajustar los limites de nuestro gráfico con el uso de los métodos plt.xlim() y plt.ylim()
Su sintaxis es:
plt.xlim(10, 100)
plt.ylim(10, 90);
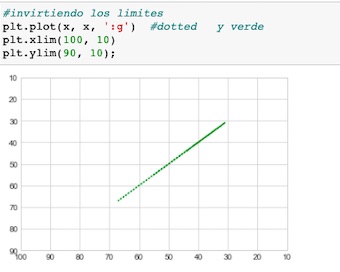
Podemos invertir los ejes, para ello bastara invertir su orden dentro del parámetro.
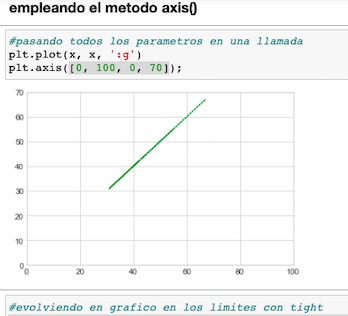
Axis
plt.axis()
Este método permite en una sola llamada, mezclar los diferentes parámetros del gráfico.
No debe confundirse axes con axis; plt.axis(), tiene una sintaxis asi
[xmin, xmax, ymin, ymax]:
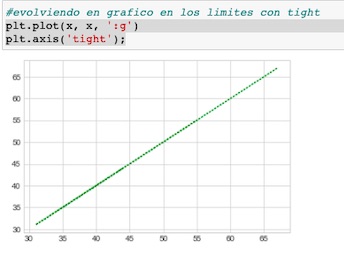
Tight
Con tight podemos envolver los limites de nuestros puntos
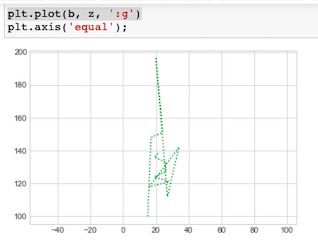
Equal
Con equal garantizamos una relación de aspectos entre ambos ejes.
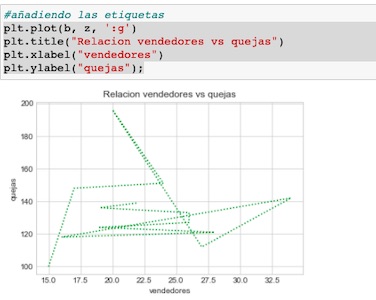
Etiquetar, nombrar e identificar el gráfico
También podemos por supuesto colocar los títulos del grafico, las leyendas etc.
Matplotlib, nos permite eso de un modo fácil.
En la imagen siguientes podemos ver ejemplos de como añadir etiquetas
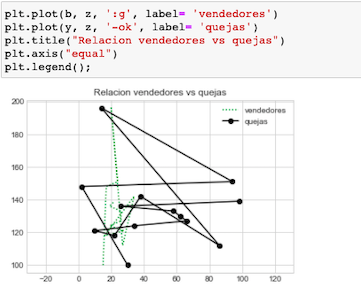
Traducir de plt.plot() a ax.plot()
Si bien la mayoría de las funciones plt se traducen directamente a métodos ax (como plt.plot () → ax.plot (), plt.legend () → ax.legend (), etc.), este no es el caso para todos los comandos. En particular, las funciones para establecer límites, etiquetas y títulos se modifican ligeramente. Para realizar la transición entre funciones de estilo MATLAB y métodos orientados a objetos, realice los siguientes cambios:
En la interfaz orientada a objetos para graficar, en lugar de llamar a estas funciones individualmente, a menudo es más conveniente usar el método ax.set () para establecer todas estas propiedades a la vez:
Hasta aquí por hoy, en otros artículos hablaré de como trabajar con otros gráficos
Espero modestamente que este artículo, sirva de ayuda a alguien.
Gracias
“Todo aquello que constituye la esencia del ser humano, encierra en si mismo, la razón de su propia extinción: el oxigeno, los sentimientos, el agua, …
Un elemento común en una aplicación es que nos toque buscar una palabra en la base de datos, en Laravel. Aquí les muestro una forma de hacerlo que funciona.
Buscando una palabra en varias columnas o en todo un modelo
Lo que haremos es crear una variable query y con el uso “use” y de orWhere, nos compare el contenido de la columna con el valor de la búsqueda.
$busqueda = 'Palabra o termino a encontrar;
$descripcion = Descripcion::from('descripcion as a')
->where(function ($query) use ($busqueda) {
$query = $query->orWhere('a.titulo','like',"%$busqueda%");
$query = $query->orWhere('a.nombre','like',"%$busqueda%");
$query = $query->orWhere('a.explicacion','like',"%$busqueda%");
$query = $query->orWhere('a.etiquetas','like',"%$busqueda%");
});
$posts = $posts->where('a.estado','=',1)
->get();
Manejando algo del código, podemos emplear Auth con el uso de modelos, y crear un sistema de autenticación mediante el uso de sus relaciones, lo cual reforzará la seguridad de nuestra web.
Ver Como Instalar Laravel En el ejemplo siguiente, creamos una función managePages(), dentro de la clase AdminPolicy, que nos indica una determinada condición para el usuario que intenta acceder, en este caso limita su uso solo a aquellos con los roles Admin y Editor. Luego declaramos su validez dentro de Providers, específicamente en el constructor del AuthServiceProvider. Para esto lo que hacemos es pasarle la ruta exacta del GateContract y una variable que nos traerá los datos del user. Con el uso de un foreach le damos un valor dinamico al acceso.
// app/Policies/AdminPolicy.php
class AdminPolicy
{
public function managePages($user)
{
return $user->hasRole(['Admin', 'Editor']);
}
}
// app/Providers/AuthServiceProvider.php
public function boot( \Illuminate\Contracts\Auth\Access\GateContract $gate)
{
foreach (get_class_methods(new \App\Policies\AdminPolicy) as $method) {
$gate->define($method, \App\Policies\AdminPolicy::class . "@{$method}");
}
$this->registerPolicies($gate);
}
Luego en cada uno de los espacios donde necesitamos acceder, colocamos una clausula de acceso, que llamara a la clase que hemos creado.
Muchas veces, nos damos cuenta de que necesitamos regresar en el tiempo a un punto de nuestro proyecto, para ello el comando checkout nos permite regresar a un commit anterior en Git, de esta manera:
git checkout 766abcd
766abcd, es el identificador del commit al que deseamos regresar. Esta operación, si lo hacemos desde una rama, no afectará a otras, de modo que puedes hacer diferentes commit a partir de ese punto, sin que se modifiquen otras ramas del proyecto.
Existen
diferentes formas de retroceder en el tiempo a commits previos, checkout es una
de ellas, pero tambien se utiliza reset con sus atributos soft o hard
Con
una sintaxis como:
git reset—soft referencia del commit
Esto
nos permitirá retroceder a un commit previo, manteniendo los cambios:
git reset—soft 568abcj
Si
queremos deshacer solo el ultimo:
git reset—soft HEAD~
Si
lo que se desea es eliminar permanentemente los cambios realizado después de un
commit específico, el comando a usar es:
git reset—hard 789abcd
Si
queremos eliminar los cambios después del ultimo commit lo que hacemos es usar
el atributo hard del comando reset, pero dirigiéndolo al apuntador especial
HEAD.
git reset—hard HEAD~
para descartar los cambios antes de retornar a un commit, se utiliza el comando stash
git commit stash
Debemos recordar siempre que poseemos una valiosa
herramienta, para obtener información sobre el estado y la estructura del árbol
del proyecto, que es el comando log.
Podemos ver la estructura de los últimos commit con este
comando
git log --oneline
Su salida, será algo
como esto
8674e5f commit test3
jº44568 commit segunda parte
55df4c2 commit de inicio.
El conocimieno y el uso de log con sus diferente posibilidades, nos permitirá manejar acertadamente, la creación de ramas, los movimientos entre ellas y los avances y retrocesos entre commits.
Y listo, esto es todo.
Espero modestamente que este artículo, sirva de ayuda a alguien.
En este caso hablaré de la diferencia entre dump y dumps, que son métodos, utilizados para serializar un objeto Python a un objeto json.
json.dump()
Serializa un objeto python como un objeto json. Se apoya en la funcion write() y soporta file como objeto.
El modulo json de Python siempre produce objetos tipo string, y no objetos byte, por tanto tiene lógica que write(), acepta cadenas (string), a modo de input.
json.dumps()
Serializa el objeto como una cadena(string) json.
Dicho de otro modo json.dump()serializa a archivos json y json.dumps() serializa a cadenas json.
Los argumentos de ambas funciones son los mismos que pueden verse aquí
Espero modestamente que este artículo, sirva de ayuda a alguien.
Ofertas, solicitudes y colaboraciones, aquí. Las preguntas las responderé tan pronto pueda, pero no quedaran sin respuesta
Sabemos que Git nos ofrece un sistema de ramas o branchs, que al igual que otras herramientas de control de versiones, soporta la administración de ramificaciones en los proyectos.
Sin ánimo de ahondar demasiado, digamos que la diferencia básica que Git aporta, es que en vez de crear un directorio adicional para guardar una nueva rama, lo hace de forma inmediata sin crear nuevos directorios, almacenando solo copias instantáneas, de como está el archivo en ese momento, junto a los nodos padres, lo cual también es una gran ventaja, al momento de gestionar la fusión entre las ramas con que contamos.
¿Que son las ramas?
Podríamos decir, si queremos ser muy escuetos que: una rama en Git es solo un apuntador en movimiento que redirige a su
respectivo commit.
Lo explico así: al iniciar un proyecto y hacer tu primer commit, estas creando una rama principal de trabajo, también llamada master.
A medida que creas tu código, y vas avanzando buscando una solución, tal vez necesites caminos alternativos, que te lleven a determinado punto y hasta tanto no lo alcances, no querrás incorporarlo a lo que has hecho en tu rama principal, incluso pudiera ser que nunca alcances ese punto, y simplemente necesites regresar adonde estabas antes.
Esto es posible hacerlo creando ramas de trabajo, o sea cada vez que creas una alternativa, podemos decir que estás trabajando en una rama, si a eso unimos, que sobre el propio proyecto, pueden estar trabajando diferentes integrantes de un equipo, tendremos varias ramificaciones, y al mismo tiempo si cada uno de ellos quiere probar nuevas rutas para buscar un resultado esperado, entonces crearán nuevas ramas, en un mismo árbol de proyecto.
Lo que hace a Git superior a otros, es el modo rápido y eficaz en que maneja las ramificaciones, haciendo el avance o el retroceso entre distintas ramas, algo ágil , cómodo y sencillo, lo cual facilita que durante el desarrollo, las ramas puedan crearse y unirse entre si, tantas veces como necesitemos.
Es fácil entender entonces, que este enorme potencial es de gran ayuda,
para agilizar y fortalecer el modo en que creamos código.
El valor del Commit
Al escribir git add . estas indicando a git que pase tus archivos a la zona conocida como stage, pero lo que sucede realmente es que se ejecuta una suma de control de ellos, en 40 caracteres (un resumen SHA-1), y se almacena un blob (copia) de cada uno en el repositorio, guardando cada suma de control, en el área de preparación (staging area):
Al crear una orden de confirmación commit, estamos diciéndole a Git que aceptamos que los cambios añadidos previamente con el add al área stage, sean procesados, y lo que hará el sistema es crear y almacenar una impresión del código de ese momento, con un grupo de metadatos explicativos como los que recoge la opción –m.
Nuestro commit, también creará un apuntador hacia esta impresión instantánea (piensa en una foto de ese momento), que permitirá identificarla, retornarla, o unirla a otra; o los apuntadores podrían ser varios, si lo que hay detrás de nuestro commit, es un merge que une varias ramas.
Suponiendo que estuvieras trabajando con 5 subdirectorios, lo que sucederá al hacer commit es que Git realizará sumas de cada uno, que guardará como objetos árbol en el repositorio Git y creará un objeto de confirmación con los metadatos y además un apuntador al objeto árbol de la raíz del proyecto.
Hecho esto, ahora habría 7 objetos en el repositorio de tu proyecto, los 5 blobs, un árbol que no es más que la lista estructurada de lo que contiene el repositorio, y la confirmación de los cambios que el commit procesó y que apunta directamente a la raíz del árbol.
Entonces, si decides hacer más cambios y confirmarlos, el siguiente commit también tendrá un apuntador que se dirige al commit previo, de esa manera queda encadenado a la versión anterior y así sucesivamente.
Por tanto, la rama se mantiene en movimiento avanzando en cada commit, ese desplazamiento comienza al crear la rama principal master, con el primer commit.
¿Cómo se crea una rama?
El comando utilizado para crear una rama es :
git branch nombre de la rama
Este comando lo que hará será crear un nuevo apuntador, disponible para que dirija al ultimo commit que has realizado.
Para crear la rama nuevo_test, escribe:
$ git branch nuevo_test
El nuevo apuntador, dirigirá al commit en el que estés.
Aunque pueda parecer complicado, no lo es.
En este punto, habrá dos ramas, cada una con su apuntador que refieren al mismo commit, sin embargo la magia está en que existe un apuntador llamado HEAD, con una labor especial que es la de apuntar a la rama local en la que te encuentres, en este caso master, pues aunque se creó la rama nuevo_test, con el comando branch, aun no se ha entrado a ella.
El comando que maneja los logs, y que debemos tener siempre a mano para saber cómo vamos, y entre otras cosas, la estructura de nuestro árbol de proyecto: git log , en su opción --decorate nos mostrará la estructura
Donde g40ac será el commit al que apuntan ambas ramas.
Moviendose entre ramas
Para moverse de una rama a la otra el comando a usar es :
git checkout
y la sintaxis si queremos ir a la rama nuevo_test es :
$ git checkout nuevo_test
Ahora el apuntador se apuntará a la rama nuevo_test
Si hacemos ahora un commit
$ git commit -a -m 'primer cambio'
Y corremos nuevamente log --decorate veremos que la rama nuevo_test apunta al nuevo commit junto al apuntado HEAD.
Si queremos regresar a la rama master, utilizaremos igualmente checkout, al hacerlo, se moverá nuevamente el apuntador HEAD a la rama master, y restituirá los archivos dejándolos tal y como estaban en el último commit de esa rama principal.
Esto, no es otra cosa que rebobinar el proyecto, dando marcha atrás en el
tiempo, por tanto los cambios que hagas
en adelante, serán diferentes de la versión anterior del proyecto.
Otro aspecto importante de Git, es que si no es capaz de realizar este rebobinado de un modo limpio, o sea si no puede recuperar la impresión exacta del ultimo commit, no permitirá hacer el checkout.
En definitiva para moverte entre ramas los comando son tres, branch que crea la rama, commit que la confirma y checkout que te permite saltar de una a otra
Por supuesto al saltar entre ramas, cada
rama tendrá diferencias en tu
labor, para ver las diferencias podemos usar el comando log de este modo:
git log --oneline --decorate --graph –all
Esto mostrará el historial de los commit, indicando dónde están los apuntadores de cada ramas y como ha variado el historial.
Si ahora analizamos lo que dijimos al inicio, sobre el modo en que se compone una rama, desde el punto de vista estructural, comprenderemos porque una rama Git es un simple archivo, con los 40 caracteres de una suma de control SHA-1, vinculado a un commit específico.
De ahí su simpleza, velocidad y eficiencia.
Y listo, esto es todo.
Espero modestamente que este artículo, sirva de ayuda a alguien.
Gracias.
….un sueño es casi todo y más que nada; más que todo al soñarlo, casi nada después……
Una cuestión muy importante en CSS, sobre todo en tiempos de mobile-first, es poder insertar una imagen responsive, capaz de verse bien en cualquier dispositivo, y esto adquiere mayor importancia cuando son imágenes de fondo.
Para hacerlo de modo exitoso es necesaria la propiedad background-size
de CSS, la cual asimila el valor cover,
que es el encargado de decir escale el alto y ancho de la imagen de forma
automática y proporcional de acuerdo a la ventana de visualización o viewport
de que se trate.
Por supuesto que varia según el tamaño de la pantalla, si para pantallas
grandes tipo PC, o televisiones, una
imagen con un tamaño de 5500x3600px es lo más adecuado, sin embargo no es lo
recomendable para dispositivos más pequeños, como móviles, por tanto la opción
de usar dos imágenes según el tamaño del display es útil y fácil de conseguir.
El uso de una imagen para una para dispositivos móviles y otra para equipos
de más alta resolución, es una practica que ayuda mucho, teniendo en
cuenta que queremos evitar que la imagen se pixele cuando se agrande, para
cubrir el tamaño de la ventana del navegador, de lo que se trata es de hallar
el tamaño adecuado, según nuestras necesidades
Para escribir la propiedad en el css, recordando que css es una hoja de cascada, por tanto las ordenes llevan un orden dado, nuestro código debería ser aproximadamente este:
// indicamos la ubicación de la imagen
background-image: url(images/background-picture.jpg);
//centramos la imagen vertical y horizontalmente */
background-position: center center;
//evitamos que el navegador repita la imagen para llenar el espacio */
background-repeat: no-repeat;
//dejamos la imagen fija de modo que no cambie si cambia la ventana del navegador, además, rescalandose
background-attachment: fixed;
// llamamos a la propiedad cover para indicar que cubrirá todo el ancho
background-size: cover;
//garantizamos que si hay un error al cargar o demora se muestre un color mientras tanto
background-color: #66999;
este código puedes escribirlo o verlo escrito también en este formato
background: #66999 url(background-photo.jpg) center center cover no-repeat fixed;
Y listo, esto es todo.
Espero modestamente que este artículo, sirva de ayuda a alguien.
La regresión lineal, es una de las técnicas más conocidas y usadas dentro de la estadística en general y la Inteligencia Artificial en particular.
Se utiliza para para estudiar la relación entre variables, de modo que permita al investigador o analista de datos, estimar como influyen en el resultado o valor de un evento, un conjunto de variables a las que se llama predictoras, o independientes.
Su popularidad se basa, en que se adapta a una extensa variedad de situaciones, abarcando campos tan disimiles como la física, la investigación social, o la economía.
Utilidad de la regresión lineal
Podríamos emplear la regresión lineal para caracterizar la relación entre elementos o variables, de modo que nos permita calibrar parámetros en física; o predecir un vasto rango de fenómenos, como el efecto de decisiones económicas, el comportamiento de las personas, o la eficacia esperada de una inversión, o de la venta de un producto, en los análisis socioeconómicos, por citar ejemplos.
En esencia, la teoría de la regresión trata de explicar (predecir o pronosticar), el comportamiento de una variable (v. dependiente) en función de otra u otras (v. independiente), partiendo del supuesto de que ambas variables comparten una relación estadística lineal.
Siendo una técnica estadística, recomiendo entender su complejidad antes de utilizarla en proyectos de inteligencia artificial, donde lenguajes como Python, R o SPSS, nos adelantan mucho trabajo.
Saber de que va, nos ayudará a entender que hacemos y comprender los resultados que obtenemos; y sobre todo cuando su aplicación puede sernos de ayuda y cuando no.
La regresión lineal no es posible analizarla con profundidad, si entre otras cosas, desconocemos los conceptos de correlación lineal y los diagramas de dispersión.
De modo resumido, digamos que la correlación lineal nos indica el nivel de relación que existe entre una variable y otra, la cual puede ser positiva o negativa.
Si es positiva significa que mientras crece una, también crece el valor de la otra y si es negativa sucede lo contrario.
Por otro lado, un diagrama de dispersión es una distribución espacial de los valores que toman están variables; por tanto nos puede ofrecer una idea bastante aproximada, sobre la relación entre ellas, incluso cuantificar de forma un tanto arcaica que grado de relación lineal existe, basta con observar la posibilidad de una recta que las una.
No obstante, en la vida real, los datos son muchos y raramente existe una relación que trace una línea perfecta, lo común y practico es todo lo contrario.
Estos ejemplos de diagramas de dispersión, son una muestra muy simple de tipos de datos, con diferentes tipos de relación, que nos ayudan a determinar la naturaleza de esta.
En definitiva el análisis de regresión lineal, ofrece una función que representa una recta en el espacio y esta recta variará su inclinación, en dependencia de como la magnitud de estas variables se comporte.
Cuando hacemos un análisis de regresión estamos pasando de expresar una dependencia estadística, a representar o buscar representar una dependencia funcional, o sea a buscar la recta que mejor se adapta a los puntos y como esto influye en su inclinación.
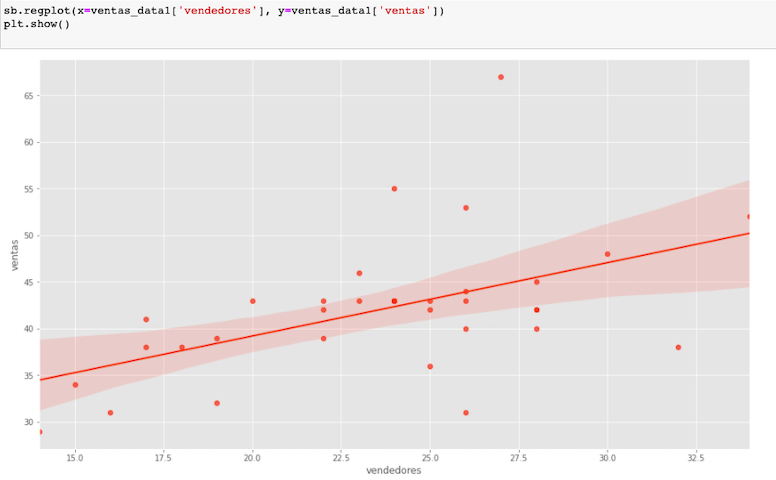
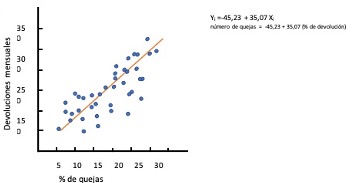
Supongamos que tenemos un conjunto de datos y necesitamos determinar en que medida se relacionan dos variables: la cantidad de quejas que emiten los clientes de un producto en internet, y la cantidad de productos devueltos en tienda.
El eje vertical muestra el número de quejas mensuales, y el horizontal el número de devoluciones mensuales expresado en porcentajes, con respecto a la venta.
A simple vista, parece existir una relación positiva entre ambas variables: conforme aumenta el número de quejas mensuales en el foro de la compañía, también aumenta el número de devoluciones mensuales.
Podríamos añadir que solo medimos artículos de una determinada categoría; entonces para describir estos datos lo mas sencillo seria decir: que si aumentan las quejas en el foro, directamente aumentan las devoluciones pero esto; aunque correcto, es poco especifico.
¿Cómo obtener una descripción más concreta de los resultados?
Tenemos la opción de listar los datos concretos de que disponemos; pero esto, aunque preciso, no resulta demasiado informativo.
O podemos describir la tendencia que se observan en la nube de puntos que representan los datos, utilizando una función matemática simple, tal como una línea recta, ya que a simple vista una línea recta podría ser el punto de partida ideal para describir resumidamente la nube de datos y es línea es la que aporta la funcion de regresion lineal.
Para poder determinar esta recta, lo primero seria determinar sus coeficientes ( B0 y B1) que son quienes definen la recta.
B1 es la pendiente de la recta: el cambio medio que se produce en el número de quejas (Yi) por cada unidad de cambio que se produce en el porcentaje de devoluciones (Xi) .
El coeficiente B0 es el punto en el que la recta corta el eje vertical: el número medio de quejas que corresponde a un mes con porcentaje de devolución cero.
Conociendo los valores de estos dos coeficientes, es fácil reproducir la recta y describir con ella la relación existente entre ambas variables.
En este modelo, vemos que la recta hace un buen seguimiento de la distribución de los datos.
La formula obtenida nos da una recta (Bi) que indica que como promedio a cada incremento en el porcentaje de quejas, corresponde un incremento devoluciones (Yi).
Nota Importante: Si vemos el inicio de la recta B0, notamos que un mes sin quejas podría tener -45 quejas, lo cual no es sencillamente posible.
Aunque el origen de B0 nos brinda información sobre lo que podría ocurrir si estimamos hacia abajo la tendencia observada en los datos, hasta llegar a un mes sin quejas partiendo del hecho de que ese caso nunca ha ocurrido, podemos cometer un error de método al pronosticar resultados en un rango de valores desconocido, lo cual es un riesgo alto e innecesario en un análisis de regresión.
Existen otras técnicas para ello, no obstante, podríamos mejorar este estudio añadiendo todos los posibles escenarios, por ejemplo hurgar en los datos hasta hallar meses con esas características.
La mejor recta de regresión
Queda claro que la mejor recta es la que se adapte a la nube de puntos, pero en la realidad ningún conjunto de datos muestra una línea que se adapte a todos, y si así sucediera, lo aconsejable, es revisar el origen de esos datos de un modo exhaustivo.
En nuestro ejemplo, seria posible trazar muchas rectas diferentes, pero entre ellas se trata de hallar, la que puede convertirse en el mejor representante del conjunto total de datos.
Existen diferentes procedimientos para hallarla, de modo que ajustemos nuestra función.
Uno de los más conocidos y usados, es aquel que hace mínima la suma de los cuadrados de las distancias verticales entre cada punto y la recta. (método de los mínimos cuadrados)
Esto significa que, de todas las rectas posibles a dibujar en nuestro conjunto de datos, existe una y solo una, que consigue que las distancias verticales entre cada punto y la recta sean mínimas.
Esta se logra se elevando todas las distancias al cuadrado para anular su signo, ya que al ser opuestas (negativas y positivas), se anularían al sumarlas.
Bondad de ajuste
El concepto bondad de ajuste, parte de la idea de que incluso la mejor recta puede no ser una buena representación de los datos.
Por tanto, hay que añadir a la recta y su formula, alguna indicación de su grado que sea precisa, o sea necesitamos información útil, que nos permita conocer con que grado de fidelidad, la recta describe la pauta de relación, que pueda existir en los datos.
¿Cómo podemos cuantificar ese mejor o peor ajuste de la recta?
Hay muchas formas de resumir el grado en el que una recta se ajusta a una nube de puntos
Podríamos utilizar la media de los residuos, o la media de los residuos en valor absoluto, o las medianas de alguna de esas medidas, o alguna función ponderada de esas medidas, etc.
Una medida de ajuste, muy usada y aceptada es calcular el cuadrado del coeficiente de correlacion R2, conocido también como coeficiente de determinación R2.
R2toma valores entre 0 y 1 (0 cuando las variables son independientes y 1 cuando entre ellas existe relación perfecta).
La utilidad de este indicador estriba en la simplicidad de su interpretación.
R2 representa el grado de ganancia o efectividad con que podemos predecir una variable, basándonos en el conocimiento que tenemos de una o más variables, dicho en lenguaje estadístico:
expresa la proporción de varianza de la variable dependiente, explicada por la variable independiente.
Si queremos, por ejemplo, pronosticar el número de devoluciones, sin conocer otra variable, podemos utilizar la media del numero de devoluciones, pero si tenemos información sobre algún otro elemento(variable) y conocemos su grado de relación con las devoluciones; el pronóstico mejorará
El valor R2 indica que si conocemos el porcentaje de devoluciones, mejoraremos en ese porciento, nuestra capacidad para conocer el numero de quejas.
Variabilidad de la regresión
Ya sea que analicemos solo dos variables, lo que en estadística se denomina regresión simple, o más de dos (regresión múltiple), el análisis de regresión lineal sigue en esencia las mismas pautas.
Como dije antes es una técnica muy útil para explorar y cuantificar la relación entre una variable llamada dependiente o criterio (Y) y una o más variables llamadas independientes o predictoras (X1, X2, …, Xn), así como para desarrollar una ecuación lineal predictiva.
Además, el análisis de regresión lleva asociados una serie de procedimientos de diagnóstico que informan sobre su idoneidad y que ofrecen ayuda para mejorarlo, no obstante es importante entender que el análisis de regresión no expresa causalidad, o sea no indica que una variable cause tal o mas cual efecto, sino que indica relación.
Esto es muy importante entenderlo y tenerlo presente.
Regresion simple
Conociendo que un análisis de regresion simple incluye una variable dependiente y una independiente o predictora, iremos directamente a conocer el significado de sus resultados
Residuos
Son las diferencias que existen entre las puntuaciones observadas y los pronósticos obtenidos en la recta.
R2 corregida:
Funciona como una corrección a la baja de R, es útil cuando los casos son pocos y las variables independientes muchas, ya que R2 puede dar valores altos artificiales o poco confiables, al considerar en su calculo p como el numero de variables independientes, mejora el ajuste.
Error típico de estimación
Normalmente es inversamente proporcional a la calidad del ajuste. En esencia es la desviación típica de los residuos y lo que mide es aquella parte de variabilidad de la variable dependiente, que no explica la recta de regresion.
Coeficientes de regresión parcial
Son los componentes de nuestro análisis, que conforman la ecuación de regresion, donde
B0 es el coeficiente que corresponde a la constante que expresa el origen de la recta
Y B1 seria la pendiente, que muestra el cambio medio que corresponde a la variable dependiente, por cada cambio en la variable independiente.
Coeficientes de regresión estandarizados
Se les conoce también como coeficientes beta, y son los coeficientes de la ecuación de regresion, que se obtiene una vez que se estandarizan la variables originales, lo cual se logra convirtiendo las puntuaciones directas en típicas. En la regresion simple su coeficiente coincide con el coeficiente de correlacion de Pearson
Puntuaciones típicas.
Explicaré muy rápido que es esto de convertir las puntuaciones de directas a típicas.
Digamos que las puntuaciones directas son las que obtenemos del estudio, o sean son aquellas que se encuentran en nuestra nube de datos, y a las que durante el análisis de regresión intentamos hallar su relación con respecto a una recta.
Sin embargo, existe un método alternativo que nos permite para expresar esas puntuaciones directas, pero con respecto al grupo de datos y es tipificando los datos .
Como puede verse, obtenemos la diferencia de la puntuación (X), con la media del grupo de datos(M) , o sea nos da la distancia al punto central de la distribución que luego dividimos entre la desviación típica.
Las puntuaciones típicas se encargan de expresar que distancia hay entre las puntuaciones directas y la Media, es decir, indican cuantas Desviaciones Típicas hay desde la puntuación hasta la Media.
Su importancia radica, en que muestra la relación entre puntuaciones con independencia de la variable, o la unidad de medida, y esto permite comparar puntuaciones en escalas diferentes.
Una nota importante es que la Media y Varianza de las distribuciones tipificadas son siempre iguales a 0 y 1.
Regresión múltiple
La regresión lineal permite realizar el análisis con mas de una variable independiente y, por lo que es posible emplear la regresión múltiple.
La cuestión es que en ese caso la ecuación de regresión, deja de definir una recta en el plano, y pasa a mostrar un hiperplano, en un espacio que es ahora multidimensional.
Esto quiere decir que si con una variable dependiente y dos independientes, necesitamos tres ejes para representar su diagrama de dispersión, para tres variables independientes necesitaremos cuatro y así sucesivamente, lo cual es poco practico e inútil
La solución es partir de la ecuación del modelo
Ahora la variable dependiente (Y), expresa la combinación lineal de un conjunto de K variables independientes (Xk), donde cada una de las cuales, posee un coeficiente (βk) que indica el peso relativo de esa variable en la ecuación.
La ecuación incluye además, una constante (β0) y un componente aleatorio que son los residuos (los residuos: ε) encargados como ya vimos antes de recoger todo lo que las variables independientes no son capaces de explicar.
Y al igual que en la regresion simple, existe una ecuación mínimo-cuadrática, que se encarga de estimar los valores de los coeficientes beta del modelo de regresión, intentando hacer que las diferencias al cuadrado entre los valores observados (Y) y los pronosticados ( ) sean mínimas, la cual tiene esta estructura.
Coeficientes parciales
Indican como incide cada variable independiente sobre la variable dependiente, manteniéndose constantes el resto de las variables independientes, o sea:
un coeficiente de correlación parcial expresa el grado de relación existente entre dos variables tras eliminar de ambas el efecto debido a terceras variables
Estos coeficientes deben ser analizados con cuidado, porque no son independientes entre sí.
El valor concreto estimado para cada coeficiente se ajusta teniendo en cuenta la presencia del resto de variables independientes, de ahí el nombre de parcial.
Tambien es importante la existencia de colinealidad (alto grado de asociación entre algunas o todas las variables independientes) en estas variables, lo que se asocia con que el signo del coeficiente de regresión parcial de una variable, pueda no ser el mismo que el del coeficiente de correlación simple entre esa variable y la dependiente.
Esta diferencia de signo, se atribuye a los ajustes que se llevan a cabo para mejorar la ecuación.
Coeficientes de regresión estandarizados en la regresión múltiple.
Ya sabemos que los coeficientes Beta están basados en las puntuaciones típicas y, por tanto, son directamente comparables entre sí, los que les permite mostrar la cantidad de cambio, en puntuaciones típicas, que se generará en la variable dependiente por cada cambio de una unidad en la correspondiente variable independiente, manteniendo constantes al resto de variables independientes.
Su valía es especialmente importante, al ser muy útiles en mostrar la importancia relativa de cada variable independiente en la ecuación de regresión.
En general, una variable tiene tanto más peso (importancia) en la ecuación de regresión, cuanto mayor (en valor absoluto) es su coeficiente de regresión estandarizado.
Y hasta aquí, ahora al obtener los resultados de un análisis de regresión o plantearte emprende uno cuando te enfrentes a un grupo de datos y un problema a resolver, espero que tengas algo mas claro que estas viendo, y porque.
Espero modestamente que este artículo, sirva de ayuda a alguien.
Gracias
El amor siempre empieza soñando y termina en insomnio