Una tarea común y cotidiana es leer un fichero línea a línea en Python, lo cual el lenguaje facilita mucho, pero no deja de ser algo que vale la pena explicar.
Para leer un fichero debemos abrirlo con la función open() y luego emplearemos un for para recorrerlo y leerlo.
Es algo así:
with open('ruta_del_fichero') as f:
for linea in f:
#codigo….
o así:
#guardamos el contenido del fichero en una variable y lo leemos
fichero = open('ruta_del_fichero', ‘r’)
leído=fichero.read()
print(leido)
Y esto es todo.
Espero sinceramente, que este post ayude a alguien.
Un ValueError en Python es aquel que se lanza cuando se asigna un valor incorrecto a un objeto.
numero = 7
lista = []
list.remove(numero)
Causas del ValueError en Python en Python.
Cuando tienes el mismo tipo de objeto, pero el valor incorrecto, Python rechaza el código.
Una equivocación común es confundir un ValueError con un TypeError.
A diferencia de ValueError, se lanzará un TypeError cuando se realiza una operación que utiliza un tipo de objeto incorrecto o no admitido.
O sea es una diferencia de tipo de objeto, no de su valor.
Aplicandolo a la vida real, si tienes un auto e intentas ponerle 5 neumaticos este es un error de valor, o sea un ValueError, por el valor de los neumáticos será como máximo 5.
Si por el contrario tuvieras un auto e intentaras meterlo en una bolsa de viaje, es una ejemplo de TypeError, porque además de que no cabe, el tipo de objeto que corresponde no es ese.
Si ves una ventana que indica un ValueError en Python analiza tu código, buscando una de esas causas.
Intentas realizar una operación cuando no existe un valor
Tratas de extraer más valores de los que tiene un objeto
El valor que esperas obtener es imposible (por ejemplo, si intentas obtener la raíz de un número negativo).
Espero haber ayudado.
El amor tiene firma de autor, en las causas perdidas
class boxeador(object):
def __init__(self, color):
self.color = color
@property
def esquina(self):
print("Bienvenido, tu color es {}".format(self.color))
def main():
a = boxeador('rojo')
e = a.esquina
if __name__ == '__main__':
main()
En este articulo mostraré como listar un directorio en python con walk. En este link podrás ver también, como acceder a directorios con scandir
El método walk() pertenece al módulo os , y recibe como parámetro la ruta del contenido que recorreremos.
Como lo que hace el método es crear un iterador, que en cada iteración, devuelve tres valores: el nombre de la ruta completa del directorio, la lista de directorios que lo componen y la lista de ficheros de ese directorio.
El recorrido que hace el metodo por defecto es descendente, por lo que primero listará el contenido del directorio actual, y luego ira descendiendo por nivel listando los directorios correspondientes.
Cuando no se especifica la ruta, walk() toma como referencia el directorio actual.
import os
dir = "/Users/blackmaster/Downloads/"
for nombre_directorio,carpetas,archivos in os.walk(dir):
print('\n A')
print(nombre_directorio)
print('\n B')
print(carpetas)
print('\n C')
print(archivos)
El resultado del script anterior irá devolviendo recursivamente, o sea por niveles los componentes de una ruta en este caso, separados por un salto de línea con los subtitulos A, B y C.
Te invito a que lo pruebes, para que lo comprendas mejor.
Si al método walk() le pasamos el argumento topdown=False:, mostrará primero el contenido de los directorios más profundos.
Como por defecto, walk() no sigue los enlaces simbólicos que encuentra en un directorio, hay que pasar el argumento followlinks=True, para que lo haga.
import os
dir = "/Users/blackmaster/Downloads/"
for nombre_directorio,carpetas,archivos in os.walk(dir, topdown=False,followlinks=True):
print('\n A')
print(nombre_directorio)
print('\n B')
print(carpetas)
print('\n C')
print(archivos)
Y hasta aquí.
Espero modestamente, que este post ayude a alguien.
Una necesidad que puede surgir al programar, es tener que comparar fechas en Python. Implementar las comparaciones no es algo complejo y para ello emplearemos operadores de comparación de uso común como <, >, <=, >=, != y otros, dentro del modulodatetime().
import datetime
# fecha in yyyy/mm/dd format
fecha_1 = datetime.datetime(2020, 4, 6)
fecha_2 = datetime.datetime(2019, 12, 30)
fecha_3 = datetime.datetime(2019, 1, 1)
# la comparacion devolvera verdadero o falso
print("La fecha_1 es mas nueva que la fecha_3 : ", fecha_1 > fecha_3)
print("La fecha_2 es mas vieja que la fecha_3 : ", fecha_2 < fecha_3)
print("La fecha_3 es igual a la fecha_1 : ", fecha_3 == fecha_1)
print("La fecha_1 no es la misma que la fecha_2 : ", fecha_1 != fecha_2)
La salida que obtenemos es :
La fecha_1 es mas nueva que la fecha_3 : True
La fecha_2 es mas vieja que la fecha_3 : False
La fecha_3 es igual a la fecha_1 : False
La fecha_1 no es la misma que la fecha_2 : True
En este otro ejemplo comparamos varias fechas que entramos por teclado.
# Entramos por teclado las fechas
dia_1, mes_1, año_1 = [int(x) for x in input("Introduzca fecha del primer envio"
"(YYYY/MM/DD) : ").split('/')]
primera = date(dia_1, mes_1, año_1)
dia_2, mes_2, año_2 = [int(x) for x in input("Introduzca fecha del segundo envio"
"(YYYY/MM/DD) : ").split('/')]
segunda = date(dia_2, mes_2, año_2)
dia_3, mes_3, año_3 = [int(x) for x in input("Introduzca fecha del tercer envio"
"(YYYY/MM/DD) : ").split('/')]
tercera = date(dia_3, mes_3, año_3)
# Check the dates
if primera == segunda:
print("Es raro que ambas se hicieran en mismo dia")
elif tercera > primera:
print("es correcto")
else:
print("Debe analizarse")
Y esto es todo, espero sinceramente que este post, sirva a alguien.
No discutas nunca con un imbécil, te llevará a su terreno y allí te ganará por experiencia
Fusionar dos diccionarios en Python 3.5, es algo que puede resultar común en nuestra aplicación.
El procedimiento varia según la versión de Python que usemos, en nuestro caso es la 3.5 , siguiendo las indicaciones de las convencionesPEP 448
Lo que obtenemos es un nuevo diccionario t , con todos los valores, donde están sobreescritos los valores del segundo diccionario (b), por los del primero (a)
Espero modestamente que este artículo, sirva de ayuda a alguien.
Gracias
“….El amor siempre empieza soñando y termina en insomnio“
En otros artículos he hablado de decoradores, en este, me referiré al uso de staticmethod en Python y sus características.
Todos sabemos que Python está orientado a objetos y que las clases son la base de su programación, por eso el uso de decoradores es una ayuda importante en el manejo de estas.
staticmethod es un decorador que nos permite usar una funcion dentro de una clase sin que esta reciba argumentos.
Su forma de escribirlo, es colocando una arroba delante
@staticmethod
Este decorador permite llamar a una clase, aunque esta aun no haya sido convertida en un objeto.
Veamos un ejemplo, que ya he empleado al hablar de decoradores antes:
class boxeador(object):
def __init__(self):
pass
@staticmethod
def esquina():
print("Has tenido suerte, tu esquina aun no tiene color")
def main():
b = boxeador()
b = b.esquina()
if __name__ == '__main__':
main()
Como ven hemos podido llamar a esquina() sin que esta tenga ningún parámetro.
Si eliminamos el decorador recibiríamos este error:
TypeError Traceback (most recent call last)
<ipython-input-22-0a10128b3e82> in <module>
12
13 if __name__ == '__main__':
---> 14 main()
<ipython-input-22-0a10128b3e82> in main()
8 def main():
9 b = boxeador()
---> 10 b = b.esquina()
11
12
TypeError: esquina() takes 0 positional arguments but 1 was given
'
Esto nos está indicando un error de tipo, que nos dice que a pesar de que la función esquina no tiene argumentos (parámetros), la hemos llamado como si lo tuviera.
Y hasta aquí, como siempre espero que sirva de ayuda a alguien.
Un saludo
Entrena duro y en silencio, que el éxito sea tu grito
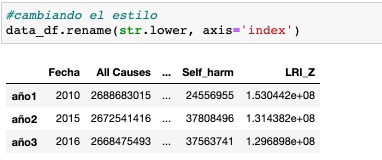
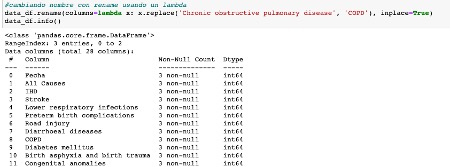
Las vías que conozco, para cambiar el nombre a una columna son tres . Podemos hacerlo con el método rename(), el cual puede aplicarse directamente a la columna, o pasarlo a través de una funcion lambda.
Ojo, es posible que haya más posibilidades, me refiero a las que uso y conozco.
Cambiar el nombre a una columna con Pandas
El método rename(), se utiliza justo para modificar la etiqueta de los ejes, al aplicarlo nos devolverá un nuevo dataframe con los valores aplicados. Su sintaxis es:
maper: Ya sea un diccionario o una función , indica las transformación a aplicar al eje dado. Este parámetro y el eje se emplean para indicar que valores y ejes recibirán el cambio.
index: Nos permite establecer el eje. Si empleamos maper, index =0 , es lo mismo que maper = index
columns: Indica las columnas, si su valor es cero o se ignora, significa que es el mismo que maper.
axis: tiene por defecto el valor 0, que indica el índice, el valor 1 indica columnas. Pueden emplearse colocando el nombre del eje(índice, columnas), o el numero (0,1). El valor que recibe por defecto es el del índice.
copy: Su valor determinado es True, y esto garantiza copiar también los datos subyacentes.
inplace: valor por defecto False, si se convierte a True, al devolver el nuevo dataframe la copia anterior se ignora.
level: valor por defecto None, indica el numero o nombre del nivel. Si existen índices multiples solo modificara en el nivel indicado.
error: acepta raise o ignore, y ese último es su valor por defecto. Ignora el error del tipo keyerror, cuando index o columns contienen etiquetas que no existen.
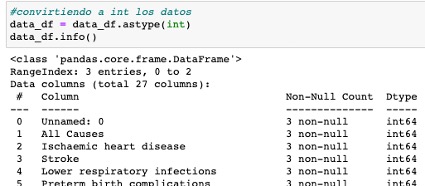
Tenemos el siguiente dataframe:
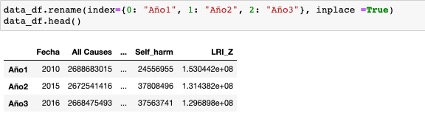
Aplicándolo directamente seria algo asi:
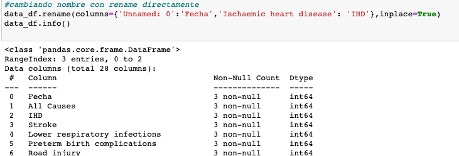
Renombramos varias columnas usando mapping en las columnas Unnamed: 0 e Ischaemic heart disease, para ello pasamos los valores nuevos, en forma de diccionario.