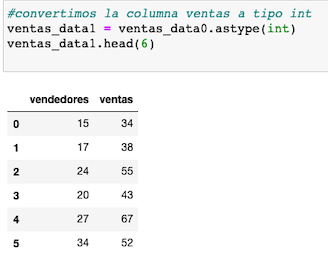
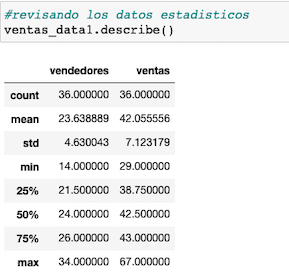
Al manejar datos, de gran volumen, que necesitamos por ejemplo guardar en archivos, para manejarlos con mayor facilidad, lo màs adecuado es emplear un modulo como Pickle, para serializarlos.
El modulo pickle de Python, de que hablaré en ese post, lo que hace es, serializar objetos para que puedan guardarse en un archivo y tener la opción de volver a cargarlos más adelante.
pickle() se utiliza para serializar y deserializar estructuras de objetos de Python, esta acción es también conocida cómo clasificación o aplanamiento de los datos.
La serialización, en su explicación más simple no es otra cosa que convertir un objeto que tenemos en la memoria, en un flujo de bytes que se puede almacenar en el disco o enviar a través de una red, y que puede ser posteriormente recuperado, transformándolo nuevamente en un objeto Python deserializado.
Las ventajas de serializar nuestros datos, no es solamente que se puedan guardar en el disco para continuar trabajando con ellos, y que podamos también enviar nuestros datos a otros por TCP, o una conexión de socket.
Pickle es igualmente poderosa porque a través de ella podemos almacenar objetos de Python en una base de datos.
Sobre todo cuando trabajamos con algoritmos de aprendizaje automático, conocer su uso nos evitará tener que reescribir todo o entrenar el modelo nuevamente, ya que podemos guardarlos y recuperarlos cuando queramos.
Datos
Pickle(), nos permite serializar los siguientes datos:
Cadenas,
Listas,
Tuplas
Enteros
Flotadores
Booleanos,
Números complejos,
Diccionarios que contienen objetos serializables.
Dataframes
Pickle(), también puede serializar las clases y funciones, incluso las lambdas. En el caso de estas últimas se usa dill(), un paquete adicional diseñado para ello, a partir de un fork de multiprocessing(), el paquete de multiprocesamiento de Python
A pesar de su capacidad, elementos como los dict predeterminados, las clases internas, o los generadores pueden tener problemas para ser serializados.
Los dicts predeterminados, necesitan ser creados con una función a nivel de módulo.
Serializando archivos
Importamos pickle()
import pickle
Creamos un diccionario y luego estructuramos un archivo de salida llamado alumnos_dic.
#escribimos un diccionario sencillo
alumnos_dict = {'Jose': 7,'Arnoldo': 8,'Mario': 5, 'Maria': 78,'Amara': 50,'Rolando': 67,'Hemeregildo': 78,'Prudencio': 79,'Zoraida': 0}
Abrimos un archivo utilizando la función open(), para poder escribirlo en formato binario. En este articulo, puede leerse un poco mas sobre las opciones para usar open().
#abrimos nuestro archivo para escribir en formarto binario
alumnos_pick= open('alumnos', 'wb')
Serializamos el archivo inicial y obtenemos un nuevo objeto file, luego cerramos la conexión
#usamos dump para serializar
pickle.dump(alumnos_dict, alumnos_pick)
alumnos_pick.close()
Deserializar nuestro archivo
El proceso de volver a cargar un archivo serializado en Python, no es complejo.
Usaremos la función open () nuevamente, pero esta vez con 'rb' como segundo argumento.
alumnos_pick.close()
Lo que haremos será leer el formato binario con que serializamos anteriormente.
#usamos dump para serializar
pickle.dump(alumnos_dict, alumnos_pick)
alumnos_pick.close()
Asignamos su valor a infile.
infile = open('alumnos','rb')
Para cargar el archivo utilizamos pickle.load (), con infile como argumento, al que asignaremos a nuevo_alumnos.
nuevo_alumnos = pickle.load(infile)
El contenido del archivo ahora está asignado a esta nueva variable.
Nuevamente, cerramos el archivo al final.
infile.close()
nuevo_alumnos
output:{'Jose': 7, 'Arnoldo': 8, 'Mario': 5, 'Maria': 78, 'Amara': 50, 'Rolando': 67, 'Hemeregildo': 78, 'Prudencio': 79, 'Zoraida': 0}
Comparamos los archivos.
#comparamos ambos archivos
print(nuevo_alumnos==alumnos_dict)
print(type(nuevo_alumnos))
output: True
<class 'dict'>
Comprimir archivos
Si el tamaño del archivo es grande, por ejemplo datasets, voluminosos, podemos ahorrar espacio comprimiendo, el archivo deserializado.
Hay diferentes vías, dos de ellas son bzip2 y gzip. Puede ver otras en este articulo.
Su diferencia en esencia, radica en que gzip es más rápido, pero los archivos que crea bzip2, ocupan la mitad de espacio que los que crea gzip.
Una cuestión importante y que puede tender a confundir es que deserializar, no es lo mismo que comprimir.
La deserialización es la conversión de un objeto de una representación (datos en la memoria de acceso aleatorio (RAM)) a otra (texto en el disco); mientras que la compresión es el proceso de codificación de datos con menos bits, para ahorrar espacio en el disco.
Lo primero es importar bz2
import bz2
Luego como primer parámetro del método BZ2File, pasaremos el nuevo nombre del nuevo archivo compactado que se creará al ejecutarse el script
sfile = bz2.BZ2File('compress_alumnos', 'w')
pickle.dump(alumnos_dict, sfile)
Multiproceso
Pickle es especialmente sensible al multiprocesamiento, pues hay elementos como las funciones lambda que no pueden ser fácilmente serializadas.
Cuando necesitamos realizar tareas complejas que ocupan mucho espacio de memoria, es común distribuir esta tarea en varios procesos.
El multiprocesamiento, es la subdivisión de un proceso en varios que se ejecutan simultáneamente, generalmente en varias Unidades Centrales de Procesamiento (CPU) o núcleos de CPU, ahorrando tiempo, como es el caso de operaciones de entrenamiento de modelos de aprendizaje automático, la creación de redes neuronales, todos ellos procesos intensivos.
En Python, esto se hace usando el paquete de multiprocesamiento multiprocessing().
La ventaja de trabajar de esta forma, es que los procesos en que se divide una tarea no comparten espacio de memoria, y comparten datos entre ellos serializados
En el ejemplo lo que haremos será crear una especie de abstracción llamada pool, para que trabaje en segundo plano procesando una tarea, y al que indicaremos cuantos procesadores empleará para ello.
#trabajando con multiprocesamiento
#importamos el modulo y creamos con la la funcion cos una tarea
import multiprocessing as mp
from math import cos
p = mp.Pool(2)
p.map(cos, range(10))
output:[1.0, 0.5403023058681398, -0.4161468365471424, -0.9899924966004454, -0.6536436208636119, 0.2836621854632263, 0.9601702866503661, 0.7539022543433046, -0.14550003380861354, -0.9111302618846769]
Si quisiéramos ejecutar en vez de cos() un lambda, nos lanzara un error, indicando que Pickle no puede serializar un lambda.
p.map(lambda x: 2**x, range(10))
output: .......
PicklingError: Can't pickle <function <lambda> at 0x7fe84683a830>: attribute lookup <lambda> on __main__ failed
Afortunadamente existe un modulo para resolver esto dill(), que pertenece a un fork, llamado pathos.multiprocessing
Pathos esta en desarrollo aun, y debe ser instalado desde github, según recomendaciones de su creador. Puedes ver este articulo en stackoverflow
El amor siempre empieza soñando y termina en insomnio
R.Arjona