Las vías que conozco, para cambiar el nombre a una columna son tres . Podemos hacerlo con el método rename(), el cual puede aplicarse directamente a la columna, o pasarlo a través de una funcion lambda.
Ojo, es posible que haya más posibilidades, me refiero a las que uso y conozco.
Cambiar el nombre a una columna con Pandas
El método rename(), se utiliza justo para modificar la etiqueta de los ejes, al aplicarlo nos devolverá un nuevo dataframe con los valores aplicados. Su sintaxis es:
dataframe.rename(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None, errors='ignore')
maper: Ya sea un diccionario o una función , indica las transformación a aplicar al eje dado. Este parámetro y el eje se emplean para indicar que valores y ejes recibirán el cambio.
index: Nos permite establecer el eje. Si empleamos maper, index =0 , es lo mismo que maper = index
columns: Indica las columnas, si su valor es cero o se ignora, significa que es el mismo que maper.
axis: tiene por defecto el valor 0, que indica el índice, el valor 1 indica columnas. Pueden emplearse colocando el nombre del eje(índice, columnas), o el numero (0,1). El valor que recibe por defecto es el del índice.
copy: Su valor determinado es True, y esto garantiza copiar también los datos subyacentes.
inplace: valor por defecto False, si se convierte a True, al devolver el nuevo dataframe la copia anterior se ignora.
level: valor por defecto None, indica el numero o nombre del nivel. Si existen índices multiples solo modificara en el nivel indicado.
error: acepta raise o ignore, y ese último es su valor por defecto. Ignora el error del tipo keyerror, cuando index o columns contienen etiquetas que no existen.
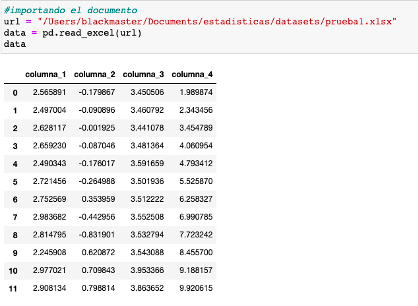
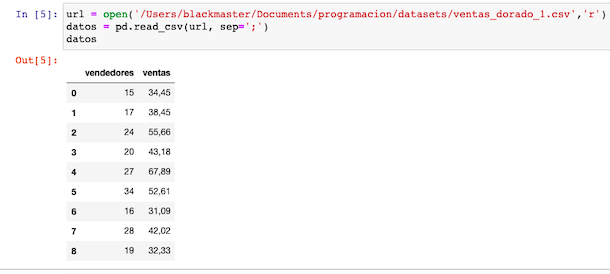
Tenemos el siguiente dataframe:
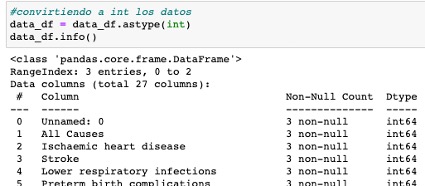
Aplicándolo directamente seria algo asi:
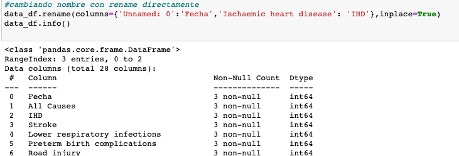
Renombramos varias columnas usando mapping en las columnas Unnamed: 0 e Ischaemic heart disease, para ello pasamos los valores nuevos, en forma de diccionario.
Renombremos ahora los indices
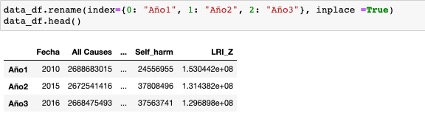
Esto también podría lograrse escribiendo
data_df.rename({0: 'Año1', 1: 'Año1', 2: 'Año3'}, axis='index')
Incluso podemos cambiar el estilo :
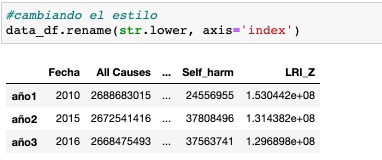
A través de una función lambda:
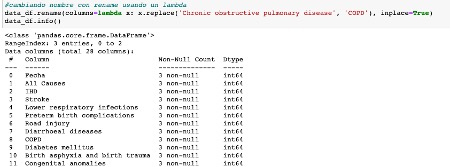
Y esto es todo
Espero modestamente que este artículo, sirva de ayuda a alguien.
Gracias
“…. hay que levantarse cada mañana con una esperanza y dormirse cada noche con una meta…“.
Y